(编者按:写完才发现,这篇分析写的又臭又长…… 原谅语言凝练不足和code阅读还没有炉火纯青,我会慢慢提炼,有兴趣的同学可以评论区吐槽:)
在看code之前,先把KVM-QEMU的source code的大框架拎出来,给读者直观一点的感受,本文最后还有一个稍微详细的call graph。中间这些文字是帮助读者以及我自己阅读和理解code的,大多数是kernel source code,因为Qemu相关的在之前的日志中已经涉及到了。
VMCS
对于Intel的虚拟化技术(VT)而言,它的软件部分基本体现在VMCS结构中(Virtual Machine Control Block)。主要通过VMCS结构来控制VCPU的运转。
- VMCS是个不超过4K的内存块。
- VMCS通过下列的指令控制:
- VMCLEAR: 清空VMCS结构
- VMREAD: 读取VMCS数据
- VMWRITE: 数据写入VMCS
- 通过VMPTR指针指向VMCS结构,该指针包含VMCS的物理地址。
VMCS包含的信息可以分为六个部分:
- Guest state area:虚拟机状态域,保存非根模式的vcpu运行状态。当VM-Exit发生,vcpu的运行状态要写入这个区域,当VM-Entry发生时,cpu会把这个区域保存的信息加载到自身,从而进入非根模式。这个过程是硬件自动完成的,软件只需要修改这个区域的信息就可以控制cpu的运转。
- Host state area:宿主机状态域,保存根模式下cpu的运行状态。在vm-exit时需要将状态加载到CPU。大概包含如下寄存器:
- CR0, CR3, CR4, RSP, RIP (都是64bit的,不支持32位)
- 段选择器CS, SS, DS, ES, FS, GS, TR,不包含LDTR。
- 基址部分FS, GS, TR, GDTR 和IDTR
- 一些MSR: IA32_SYSENTER_CS, IA32_SYSENTER_ESP,IA32_SYSENTER_EIP, IA32_PERF_GLOBAL_CTRL, IA32_PAT, IA32_EFER。
- VM-Execution control filelds:包括page fault控制,I/O位图地址,CR3目标控制,异常位图,pin-based运行控制(异步事件),processor-based运行控制(同步事件)。这个域可以设置哪些指令触发VM-Exit。触发VM-Exit的指令分为无条件指令和有条件指令,这里设置的是有条件指令。(SDM 24.6)
- VM-entry contorl filelds:包括‘vm-entry控制’,‘vm-entry MSR控制’和‘VM-Entry事件注入’。(SDM 24.8)
- VM-exit control filelds:包括’VM-Exit控制’,’VM-Exit MSR控制’。(SDM 24.7)
- VM退出信息:这个域保存VM-Exit退出时的信息,并且描述原因。(SDM 24.9)
有了VMCS结构后,对虚拟机的控制就是读写VMCS结构。后面对VCPU设置中断,检查状态实际上都是在读写VMCS结构。在vmx.c文件给出了intel定义的VMCS结构的内容。 struct __packed vmcs12
CPU 虚拟化
创建VM
1 | virt/kvm/kvm_main.c: (有所省略) |
调用了函数kvm_create_vm,然后是创建一个文件,这个文件的作用是提供对vm的io_ctl控制。
1 | virt/kvm/kvm_main.c:(简略) |
可以看到,这个函数首先是申请一个kvm结构。然后执行初始化工作。
初始化第一步是把kvm的mm结构设置为当前进程的mm。我们知道,mm结构反应了整个进程的内存使用情况,也包括进程使用的页目录信息。
然后是初始化io bus和eventfd。这两者和设备io有关。
最后把kvm加入到一个全局链表头。通过这个链表头,可以遍历所有的vm虚拟机。
创建VCPU
创建VM之后,就是创建VCPU。
1 | virt/kvm/kvm_main.c: |
从代码可见,分别调用相关cpu提供的vcpu_create和vcpu_setup来完成vcpu创建。
1 | arch/x86/kvm/vmx.c: |
首先申请一个vcpu_vmx结构,然后初始化vcpu_vmx。
MSR寄存器是cpu模式寄存器,所以要分别为guest 和host申请页面,这个页面要保存MSR寄存器的信息。然后申请一个vmcs结构。然后调用vmx_vcpu_setup设置vcpu工作在实模式。
1 | arch/x86/kvm/vmx.c: |
这个函数到这里之所以列这么而详细,其实因为也不是很确定需要保留那几个,那就索性加深下印象吧,记住Kernel对虚拟机VT-X是如何操作的——读写VMCS结构体。一堆的寄存器和控制信息,具体的都在SDM Vol3 第24章里面描述的。只重点聊下其中的几个地方:
设置CPU_BASED控制器(VMCS的一部分);GUEST中断状态寄存器;CR3,CR0 以及各种段选寄存器CS, DS, ES;之后,要保存host的MSR寄存器的值到前面分配的guest_msrs页面; Guest PML地址等等……
VCPU运行
推动vcpu运行,启动虚拟机开始运行,主要在vcpu_run函数执行。
1 | arch/x86/kvm/x86.c: |
这里理解的关键是vcpu_enter_guest进入了Guest,然后一直是vcpu在运行,当退出这个函数的时候,虚拟机已经执行了VM-Exit指令,也就是说,已经退出了虚拟机,进入根模式了。
退出之后,要检查退出的原因。如果有时钟中断发生,则插入一个时钟中断,如果是用户空间的中断发生,则退出原因要填写为KVM_EXIT_INTR。
注意一点的是,对于导致退出的事件,vcpu_enter_guest函数里面已经处理了一部分,处理的是虚拟机本身运行导致退出的事件。虚拟机一旦退出后,执行vmx_handle_exit。比如虚拟机内部写磁盘io导致退出,就在vcpu_enter_guest里面处理(只是设置了退出的原因为io,并没有真正执行io)。KVM是如何知道退出的原因的?这个就是vmcs结构的作用了,vmcs结构里面有VM-Exit的信息。
退出VM之后,如果内核没有完成处理,那么要退出内核到QEMU进程。然后是QEMU进程要处理.后面io处理时,我们再看下QEMU的处理过程
1 | arch/x86/kvm/x86.carch/x86/kvm/x86.c: |
首先要装载mmu,然后注入事件,像中断,异常什么的。然后调用cpu架构相关的run函数(vmx_vcpu_run),这个函数里面调用__vmx_vcpu_run这是一个用汇编实现的函数在vmx/vmenter.S里面,用来进入虚拟机以及指定从虚拟机退出的执行地址。最后调用cpu的handle_exit,用来从vmcs读取退出的信息。
下面展开函数vmx_vcpu_run,这个函数实在是……需要对照SDM一行一行的看,已无力分析,那就看原文中的注释简单的了解个大概就好了,他日如果有机会做这部分code,定努力哈哈哈~~1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154arch/x86/kvm/vmx.c:
static void __noclone vmx_vcpu_run(struct kvm_vcpu *vcpu)
{
struct vcpu_vmx *vmx = to_vmx(vcpu);
unsigned long cr3, cr4, evmcs_rsp;
/* Record the guest's net vcpu time for enforced NMI injections. */
if (unlikely(!enable_vnmi &&
vmx->loaded_vmcs->soft_vnmi_blocked))
vmx->loaded_vmcs->entry_time = ktime_get();
/* Don't enter VMX if guest state is invalid, let the exit handler
start emulation until we arrive back to a valid state */
if (vmx->emulation_required)
return;
if (vmx->ple_window_dirty) {
vmx->ple_window_dirty = false;
vmcs_write32(PLE_WINDOW, vmx->ple_window);
}
if (vmx->nested.need_vmcs12_sync) {
/*
* hv_evmcs may end up being not mapped after migration (when
* L2 was running), map it here to make sure vmcs12 changes are
* properly reflected.
*/
if (vmx->nested.enlightened_vmcs_enabled &&
!vmx->nested.hv_evmcs)
nested_vmx_handle_enlightened_vmptrld(vcpu, false);
if (vmx->nested.hv_evmcs) {
copy_vmcs12_to_enlightened(vmx);
/* All fields are clean */
vmx->nested.hv_evmcs->hv_clean_fields |=
HV_VMX_ENLIGHTENED_CLEAN_FIELD_ALL;
} else {
copy_vmcs12_to_shadow(vmx);
}
vmx->nested.need_vmcs12_sync = false;
}
if (test_bit(VCPU_REGS_RSP, (unsigned long *)&vcpu->arch.regs_dirty))
vmcs_writel(GUEST_RSP, vcpu->arch.regs[VCPU_REGS_RSP]);
if (test_bit(VCPU_REGS_RIP, (unsigned long *)&vcpu->arch.regs_dirty))
vmcs_writel(GUEST_RIP, vcpu->arch.regs[VCPU_REGS_RIP]);
cr3 = __get_current_cr3_fast();
if (unlikely(cr3 != vmx->loaded_vmcs->host_state.cr3)) {
vmcs_writel(HOST_CR3, cr3);
vmx->loaded_vmcs->host_state.cr3 = cr3;
}
cr4 = cr4_read_shadow();
if (unlikely(cr4 != vmx->loaded_vmcs->host_state.cr4)) {
vmcs_writel(HOST_CR4, cr4);
vmx->loaded_vmcs->host_state.cr4 = cr4;
}
atomic_switch_perf_msrs(vmx);
vmx_update_hv_timer(vcpu);
/*
* If this vCPU has touched SPEC_CTRL, restore the guest's value if
* it's non-zero. Since vmentry is serialising on affected CPUs, there
* is no need to worry about the conditional branch over the wrmsr
* being speculatively taken.
*/
x86_spec_ctrl_set_guest(vmx->spec_ctrl, 0);
vmx->__launched = vmx->loaded_vmcs->launched;
evmcs_rsp = static_branch_unlikely(&enable_evmcs) ?
(unsigned long)¤t_evmcs->host_rsp : 0;
//大概kernel 4.19之后的版本,这个部分汇编被已到了__vmx_vcpu_run
asm(
/* Store host registers */
"push %%" _ASM_DX "; push %%" _ASM_BP ";"
......
/* Avoid VMWRITE when Enlightened VMCS is in use */
"test %%" _ASM_SI ", %%" _ASM_SI " \n\t"
......
/* Reload cr2 if changed */
"mov %c[cr2](%0), %%" _ASM_AX " \n\t"
......
/* Check if vmlaunch of vmresume is needed */
"cmpl $0, %c[launched](%0) \n\t"
/* Load guest registers. Don't clobber flags. */
"mov %c[rax](%0), %%" _ASM_AX " \n\t"
......
/* Enter guest mode */
"jne 1f \n\t"
__ex("vmlaunch") "\n\t"
"jmp 2f \n\t"
"1: " __ex("vmresume") "\n\t"
"2: "
/* Save guest registers, load host registers, keep flags */
"mov %0, %c[wordsize](%%" _ASM_SP ") \n\t"
"pop %0 \n\t"
......
/*
* Clear host registers marked as clobbered to prevent
* speculative use.
*/
[rdx]"i"(offsetof(struct vcpu_vmx, vcpu.arch.regs[VCPU_REGS_RDX])),
);
/*
* We do not use IBRS in the kernel. If this vCPU has used the
* SPEC_CTRL MSR it may have left it on; save the value and
* turn it off.
*/
if (unlikely(!msr_write_intercepted(vcpu, MSR_IA32_SPEC_CTRL)))
vmx->spec_ctrl = native_read_msr(MSR_IA32_SPEC_CTRL);
x86_spec_ctrl_restore_host(vmx->spec_ctrl, 0);
/* Eliminate branch target predictions from guest mode */
vmexit_fill_RSB();
/* All fields are clean at this point */
if (static_branch_unlikely(&enable_evmcs))
current_evmcs->hv_clean_fields |=
HV_VMX_ENLIGHTENED_CLEAN_FIELD_ALL;
/* MSR_IA32_DEBUGCTLMSR is zeroed on vmexit. Restore it if needed */
if (vmx->host_debugctlmsr)
update_debugctlmsr(vmx->host_debugctlmsr);
/*
* The sysexit path does not restore ds/es, so we must set them to
* a reasonable value ourselves.
*/
loadsegment(ds, __USER_DS);
loadsegment(es, __USER_DS);
vcpu->arch.regs_avail = ~((1 << VCPU_REGS_RIP) | (1 << VCPU_REGS_RSP)
| (1 << VCPU_EXREG_RFLAGS)
| (1 << VCPU_EXREG_PDPTR)
| (1 << VCPU_EXREG_SEGMENTS)
| (1 << VCPU_EXREG_CR3));
vcpu->arch.regs_dirty = 0;
vmx->exit_reason = vmx->fail ? 0xdead : vmcs_read32(VM_EXIT_REASON);
if (vmx->fail || (vmx->exit_reason & VMX_EXIT_REASONS_FAILED_VMENTRY))
return;
vmx->loaded_vmcs->launched = 1;
vmx->idt_vectoring_info = vmcs_read32(IDT_VECTORING_INFO_FIELD);
vmx_complete_atomic_exit(vmx);
vmx_recover_nmi_blocking(vmx);
vmx_complete_interrupts(vmx);
}
‘中断’从来都是很意外的出现,我们分析也不例外没有过度令补丁的——我们简单看下中断的注入函数。
1 | arch/x86/kvm/vmx.c: |
可以看到,实际上注入中断就是写vmcs里面的VM_ENTRY_INTR_INFO_FIELD这个域。然后在vcpu的run函数里面设置cpu进入非根模式,vcpu会自动检查vmcs结构,然后注入中断,这是硬件自动完成的工作。而处理中断,这就是另外一个故事了,不知道后面有没有篇幅和时间继续看下吧。:p
调度
KVM只是个内核模块,虚拟机实际上是运行在QEMU的进程上下文中。所以VCPU的调度实际上直接使用了LINUX自身的调度机制。也就是linux自身的进程调度机制。
QEMU可以设置每个VCPU都运作在一个线程中。
1 | static void qemu_kvm_start_vcpu(CPUState *cpu) |
从Qemu的代码,看到Qemu启动了一个kvm_cpu_thread线程。其主线程函数qemu_kvm_cpu_thread_fn内循环调用kvm_cpu_exec函数,前面已经有一篇文章KVM 虚拟化原理2— QEMU启动过程大概了解了。
1 | int kvm_cpu_exec(CPUState *env) |
这个函数就是调用了前面分析过的KVM_RUN。回顾一下前面的分析,KVM_RUN就进入了虚拟机,如果从虚拟化退出到这里,那么Qemu要处理退出的事件。这些事件,可能是因为io引起的KVM_EXIT_IO,也可能是内部错误引起的KVM_EXIT_INTERNAL_ERROR。如果事件没有被完善处理,那么要停止虚拟机。
中断
如何向vcpu注入中断?是通过向真实CPU模拟注入NMI(非可屏蔽中断)中断来实现。
KVM要模拟一个中断控制芯片,这个是通过KVM_CREATE_IRQCHIP来实现的。
然后,如果Qemu想注入一个中断,就通过KVM_IRQ_LINE实现。这个所谓中断控制芯片只是在内存中存在的结构,kvm通过软件方式模拟了中断的机制。
KVM_CREATE_IRQCHIP实际上调用了kvm_pic_init这个函数。
1 | qemu-2.5.1/kvm-all.c: |
IRQ的初始化就在kvm_init中,通过调用KVM_CREATE_IRQCHIP就搞定。
而KVM_IRQ_LINE实际上依旧是通过IOCTL在kernel中完成的。进到Kernel里面:
1 | kvm-all.c |
从注释中可以看到,因为不能判断Guest使用的是PIC还是APIC,所以为每一个中断路由都设置中断。PIC就是传统的中断控制器8259,x86体系最初使用的中断控制器。后来,又推出了APIC,也就是高级中断控制器。APIC为支持多核架构做了更多的设计。实际上,在kvm模拟中,既有PIC的模拟,也有APIC的模拟。如果使用PIC的话,这里的这个set函数,其实就是kvm_pic_set_irq1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19arch/x86/kvm/i8259.c
int kvm_pic_set_irq(struct kvm_pic *s, int irq, int irq_source_id, int level)
{
int ret, irq_level;
BUG_ON(irq < 0 || irq >= PIC_NUM_PINS);
pic_lock(s);
irq_level = __kvm_irq_line_state(&s->irq_states[irq],
irq_source_id, level);
ret = pic_set_irq1(&s->pics[irq >> 3], irq & 7, irq_level);
pic_update_irq(s);
trace_kvm_pic_set_irq(irq >> 3, irq & 7, s->pics[irq >> 3].elcr,
s->pics[irq >> 3].imr, ret == 0);
pic_unlock(s);
return ret;
}
可以看到,前面申请的kvm_pic结构作为参数被引入。然后设置irq到这个结构的pic成员。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16arch/x86/kvm/i8259.c !!
static void pic_update_irq(struct kvm_pic *s)
{
int irq2, irq;
irq2 = pic_get_irq(&s->pics[1]);
if (irq2 >= 0) {
/*
* if irq request by slave pic, signal master PIC
*/
pic_set_irq1(&s->pics[0], 2, 1);
pic_set_irq1(&s->pics[0], 2, 0);
}
irq = pic_get_irq(&s->pics[0]);
pic_irq_request(s->kvm, irq >= 0);
}
此时调用irq_request,就是初始化中断芯片时候绑定的函数pic_irq_request。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29arch/x86/kvm/i8259.c:
void kvm_pic_update_irq(struct kvm_pic *s)
{
pic_lock(s);
pic_update_irq(s);
pic_unlock(s);
}
static void pic_unlock(struct kvm_pic *s)
__releases(&s->lock)
{
bool wakeup = s->wakeup_needed;
struct kvm_vcpu *vcpu;
int i;
s->wakeup_needed = false;
spin_unlock(&s->lock);
if (wakeup) {
kvm_for_each_vcpu(i, vcpu, s->kvm) {
if (kvm_apic_accept_pic_intr(vcpu)) {
kvm_make_request(KVM_REQ_EVENT, vcpu);
----> kvm_vcpu_kick(vcpu);
return;
}
}
}
}
可以看到irq_request之后会调用kvm_vcpu_kick。我们知道,对一个注入的中断来说,需要vcpu立即响应,但是在多核的架构下(smp),目的cpu可能正在运行,所以要提供一种机制停止目的cpu的运行,让它立即处理注入的中断。kvm_vcpu_kick就是给目的cpu发送一个处理器间中断(IPI),让目的cpu停止运行。
1 | arch/alpha/kernel/smp.c: |
等VM-exit退出后,就接上了前文分析过的部分。VCPU再次进入虚拟机的时候,通过inject_pengding_event检查中断。这个检查的过程就发现了通过KVM_IRQ_LINE注入的中断,然后就是写vmcs结构了注入中断,已经分析过了。
VCPU的内存虚拟化
在KMV初始化的时候,要检查是否支持vt里面的EPT扩展技术。如果支持,enable_ept这个变量置为1,然后设置tdp_enabled为1。TDP就是两维页表。为表述方便,给出kvm中下列名字的定义:
- GPA:guest机物理地址
- GVA:guest机虚拟地址
- HVA:host机虚拟地址
- HPA:host机物理地址
虚拟机页表初始化
在vcpu初始化的时候,要调用kvm_init_mmu来设置不同的内存虚拟化方式。1
2
3
4
5
6
7
8
9
10
11
12void kvm_init_mmu(struct kvm_vcpu *vcpu, bool reset_roots)
{
......
/*嵌套虚拟化,我们暂不考虑吧 */
if (mmu_is_nested(vcpu))
init_kvm_nested_mmu(vcpu);
else if (tdp_enabled)
init_kvm_tdp_mmu(vcpu);
else
init_kvm_softmmu(vcpu);
}
设置两种方式,一种是支持EPT的方式,另种是soft mmu,也就是影子页表的方式。在支持EPT的情况下,会调用init_kvm_tdp_mmu函数初始化MMU。在该函数中1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45arch/x86/kvm/mmu.c:
static void init_kvm_tdp_mmu(struct kvm_vcpu *vcpu)
{
struct kvm_mmu *context = vcpu->arch.mmu;
union kvm_mmu_role new_role =
kvm_calc_tdp_mmu_root_page_role(vcpu, false);
new_role.base.word &= mmu_base_role_mask.word;
if (new_role.as_u64 == context->mmu_role.as_u64)
return;
context->mmu_role.as_u64 = new_role.as_u64;
---> context->page_fault = tdp_page_fault;
context->sync_page = nonpaging_sync_page;
context->invlpg = nonpaging_invlpg;
context->update_pte = nonpaging_update_pte;
---> context->shadow_root_level = kvm_x86_ops->get_tdp_level(vcpu);
context->direct_map = true;
context->set_cr3 = kvm_x86_ops->set_tdp_cr3;
context->get_cr3 = get_cr3;
context->get_pdptr = kvm_pdptr_read;
context->inject_page_fault = kvm_inject_page_fault;
if (!is_paging(vcpu)) {
context->nx = false;
context->gva_to_gpa = nonpaging_gva_to_gpa;
context->root_level = 0;
} else if (is_long_mode(vcpu)) {
context->nx = is_nx(vcpu);
context->root_level = is_la57_mode(vcpu) ?
PT64_ROOT_5LEVEL : PT64_ROOT_4LEVEL;
reset_rsvds_bits_mask(vcpu, context);
context->gva_to_gpa = paging64_gva_to_gpa;
} else if (is_pae(vcpu)) {
context->nx = is_nx(vcpu);
context->root_level = PT32E_ROOT_LEVEL;
reset_rsvds_bits_mask(vcpu, context);
context->gva_to_gpa = paging64_gva_to_gpa;
} else {
context->nx = false;
context->root_level = PT32_ROOT_LEVEL;
reset_rsvds_bits_mask(vcpu, context);
context->gva_to_gpa = paging32_gva_to_gpa;
}
EPT初始化的内容挺多,还是挑几个喜闻乐见的聊下吧。kvm_x86_ops->get_tdp_level(vcpu)可以看出来EPT目前用的默认是4级页表,满足条件的会使用5级页表。
vcpu->arch.walk_mmu.pagefault被初始化成tdp_page_fault。下面看下tdp_page_fault。
1 | arch/x86/kvm/mmu.c: |
该函调用mmu_topup_memory_caches函数进行缓存池的分配,解释是为了避免在运行时分配空间失败,这里提前分配足额的空间,便于运行时使用。然后调用mapping_level函数判断当前gfn对应的slot是否可用。为什么要进行这样的判断呢?在if内部可以看到是获取level,如果当前GPN对应的slot可用,我们就可以获取分配slot的pagesize,然后得到最低级的level,比如如果是2M的页,那么level就为2,为4K的页,level就为1.
接着调用了fast_page_fault尝试快速处理violation,只有当GFN对应的物理页存在且violation是由读写操作引起的,才可以使用快速处理。
假设这里不能快速处理,那么到后面就调用try_async_pf函数根据GFN获取对应的PFN,这个过程具体来说需要首先获取GFN对应的slot,转化成HVA,接着就是正常的HOST地址翻译的过程了,如果HVA对应的地址并不在内存中,还需要HOST自己处理缺页中断。
接着调用transparent_hugepage_adjust对level和gfn、pfn做出调整。紧着着就调用了__direct_map函数,该函数是构建页表的核心函数:
1 | arch/x86/kvm/mmu.c: |
首先进入的便是for_each_shadow_entry,用于根据GFN遍历EPT页表的对应项,这点后面会详细解释。循环中首先判断entry的level和请求的level是否相等,相等说明该entry处引起的violation,即该entry对应的下级页或者页表不在内存中,或者直接为NULL。
如果level不相等,就进入后面的if判断,这是判断该entry对应的下一级页是否存在,如果不存在需要重新构建,存在就直接向后遍历,即对比二级页表中的entry。整个处理流程就是这样,根据GPA组逐层查找EPT,最终level相等的时候,就根据最后一层的索引定位一个PTE,该PTE应该指向的就是GFN对应的PFN,那么这时候set spite就可以了。最好的情况就是最后一级页表中的entry指向的物理页被换出外磁盘,这样只需要处理一次EPT violation,而如果在初始全部为空的状态下访问,每一级的页表都需要重新构建,则需要处理四次EPTviolation,发生4次VM-exit。
构建页表的过程即在level相等之前,发现需要的某一级的页表项为NULL,就调用kvm_mmu_get_page获取一个page,然后调用link_shadow_page设置页表项指向page,
看下kvm_mmu_get_page函数:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78arch/x86/kvm/mmu.c:
static struct kvm_mmu_page *kvm_mmu_get_page(struct kvm_vcpu *vcpu,
gfn_t gfn,
gva_t gaddr,
unsigned level,
int direct,
unsigned access,
u64 *parent_pte)
{
union kvm_mmu_page_role role;
unsigned quadrant;
struct kvm_mmu_page *sp;
bool need_sync = false;
role = vcpu->arch.mmu.base_role;
role.level = level;
role.direct = direct;
if (role.direct)
role.cr4_pae = 0;
role.access = access;
/*quadrant 对应页表项的索引,来自于GPA*/
if (!vcpu->arch.mmu.direct_map
&& vcpu->arch.mmu.root_level <= PT32_ROOT_LEVEL) {
quadrant = gaddr >> (PAGE_SHIFT + (PT64_PT_BITS * level));
quadrant &= (1 << ((PT32_PT_BITS - PT64_PT_BITS) * level)) - 1;
role.quadrant = quadrant;
}
/*根据gfn遍历KVM维护的mmu_page_hash哈希链表*/
---> for_each_gfn_sp(vcpu->kvm, sp, gfn) {
/**/
if (is_obsolete_sp(vcpu->kvm, sp))
continue;
if (!need_sync && sp->unsync)
need_sync = true;
if (sp->role.word != role.word)
continue;
if (sp->unsync && kvm_sync_page_transient(vcpu, sp))
break;
/*设置sp->parent_pte=parent_pte*/
mmu_page_add_parent_pte(vcpu, sp, parent_pte);
if (sp->unsync_children) {
kvm_make_request(KVM_REQ_MMU_SYNC, vcpu);
kvm_mmu_mark_parents_unsync(sp);
} else if (sp->unsync)
kvm_mmu_mark_parents_unsync(sp);
__clear_sp_write_flooding_count(sp);
trace_kvm_mmu_get_page(sp, false);
return sp;
}
/*如果根据页框号没有遍历到合适的page,就需要重新创建一个页*/
++vcpu->kvm->stat.mmu_cache_miss;
--> sp = kvm_mmu_alloc_page(vcpu, parent_pte, direct);
if (!sp)
return sp;
/*设置其对应的客户机物理页框号*/
sp->gfn = gfn;
sp->role = role;
/*把该也作为一个节点加入到哈希表相应的链表汇总*/
hlist_add_head(&sp->hash_link,
&vcpu->kvm->arch.mmu_page_hash[kvm_page_table_hashfn(gfn)]);
if (!direct) {
if (rmap_write_protect(vcpu->kvm, gfn))
kvm_flush_remote_tlbs(vcpu->kvm);
if (level > PT_PAGE_TABLE_LEVEL && need_sync)
kvm_sync_pages(vcpu, gfn);
account_shadowed(vcpu->kvm, gfn);
}
sp->mmu_valid_gen = vcpu->kvm->arch.mmu_valid_gen;
/*暂时对所有表项清零*/
init_shadow_page_table(sp);
trace_kvm_mmu_get_page(sp, true);
return sp;
}
一个kvm_mmu_page对应于一个kvm_mmu_page_role,kvm_mmu_page_role记录对应page的各种属性。下面for_each_gfn_sp是一个遍历链表的宏定义,KVM为了根据GFN查找对应的kvm_mmu_page,用一个HASH数组记录所有的kvm_mmu_page,每一个表项都是一个链表头,即根据GFN获取到的HASH值相同的,位于一个链表中。这也是HASH表处理冲突常见方法。
如果在对应链表中找到一个合适的页(怎么算是合适暂且不清楚),就直接利用该页,否则需要调用kvm_mmu_alloc_page函数重新申请一个页,主要是申请一个kvm_mmu_page结构和一个存放表项的page,这就用到了之前我们说过的三种缓存,不过这里只用到了两个,分别是mmu_page_header_cache和mmu_page_cache。这样分配好后,把对应的kvm_mmu_page作为一个节点加入到全局的HASH链表中,然后对数组项清零,最后返回sp.
linux为不同的cpu提供不同的页表层级。64位cpu使用了四级页表PT64_ROOT_4LEVEL,同时设定页表根地址为无效,此时页表尚未分配。
何时真正分配vcpu的页表?是在vcpu_enter_guest的开始位置,通过调用kvm_mmu_reload实现。1
2
3
4
5
6
7arch/x86/kvm/mmu.h:
static inline int kvm_mmu_reload(struct kvm_vcpu *vcpu)
{ /*页表根地址不是无效的,则退出,不用分配。*/
if (likely(vcpu->arch.mmu.root_hpa != INVALID_PAGE))
return 0;
return kvm_mmu_load(vcpu);
}
首先检查页表根地址是否无效,如果无效,则调用kvm_mmu_load。
1 | arch/x86/kvm/mmu.c: |
mmu_alloc_roots这个函数要申请内存,作为根页表使用,同时root_hpa指向根页表的物理地址。然后可以看到,vcpu中cr3寄存器的地址要指向这个根页表的物理地址。
虚拟机物理地址
我们已经分析过,kvm的虚拟机实际上运行在Qemu的进程上下文中。于是,虚拟机的物理内存实际上是Qemu进程的虚拟地址。Kvm要把虚拟机的物理内存分成几个slot。这是因为,对计算机系统来说,物理地址是不连续的,除了bios和显存要编入内存地址,IO设备的内存也可能映射到内存,所以内存实际上是分为一段段的。
Qemu通过KVM_SET_USER_MEMORY_REGION来为虚拟机设置内存。
1 | virt/kvm/kvm_main.c: |
就是创建一个新的memslot,代替原来的memslot。一个内存slot,最重要部分是指定了vm的物理地址,使用函数gfn_to_hva可以把gfn转换为hva。可见,一个memslot就是建立了GPA到HVA的映射关系。
内存虚拟化过程
这里,有必要描述一下内存虚拟化的过程:
VM要访问GVA地址x,那么首先查询VM的页表得到PTE(页表项),通过PTE将GVA x映射到物理地址GPA y. GPA y此时不存在,发生页缺失。KVM接管。从memslot,可以知道GPA对应的其实是HVA x’,然后从HVA x’,可以查找得到HPA y’,然后将HPA y’这个映射写入到页表。
VM再次存取GVA x,这是从页表项已经可以查到HPA y’了,内存可正常访问。
首先,从page_fault处理开始。从前文的分析,知道VM里面的异常产生VM-Exit,然后由各自cpu提供的处理函数处理。对intel的vt技术,就是handle_exception这个函数。
1 | arch/x86/kvm/vmx.c: |
从这个函数,可以看到对vmcs的使用。通过读vmcs的域,可以获得退出vm的原因。如果是page_fault引起,则调用kvm_mmu_page_fault去处理。
1 | arch/x86/kvm/mmu.c: |
这里调用了MMU的page_fault处理函数。这个函数就是前面初始化时候设置的paging64_page_fault。也就是通过FNAME宏展开的FNAME(page_fault)。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62arch/x86/kvm/paging_tmpl.h:
static int FNAME(page_fault)(struct kvm_vcpu *vcpu, gva_t addr,
u32 error_code)
{
/*查guest页表,物理地址是否存在 */
r = FNAME(walk_addr)(&walker, vcpu, addr, write_fault, user_fault,
fetch_fault);
/*页还没映射,交Guest OS处理 */
if (!r) {
pgprintk("%s: guest page fault\n", __func__);
----> inject_page_fault(vcpu, addr, walker.error_code);
vcpu->arch.last_pt_write_count = 0; /* reset fork detector */
return 0;
}
if (walker.level >= PT_DIRECTORY_LEVEL) {
level = min(walker.level, mapping_level(vcpu, walker.gfn));
walker.gfn = walker.gfn & ~(KVM_PAGES_PER_HPAGE(level) - 1);
}
----> if (try_async_pf(vcpu, prefault, walker.gfn, addr, &pfn, write_fault,
&map_writable))
return RET_PF_RETRY;
if (handle_abnormal_pfn(vcpu, addr, walker.gfn, pfn, walker.pte_access, &r))
return r;
/*
* Do not change pte_access if the pfn is a mmio page, otherwise
* we will cache the incorrect access into mmio spte.
*/
if (write_fault && !(walker.pte_access & ACC_WRITE_MASK) &&
!is_write_protection(vcpu) && !user_fault &&
!is_noslot_pfn(pfn)) {
walker.pte_access |= ACC_WRITE_MASK;
walker.pte_access &= ~ACC_USER_MASK;
/*
* If we converted a user page to a kernel page,
* so that the kernel can write to it when cr0.wp=0,
* then we should prevent the kernel from executing it
* if SMEP is enabled.
*/
if (kvm_read_cr4_bits(vcpu, X86_CR4_SMEP))
walker.pte_access &= ~ACC_EXEC_MASK;
}
spin_lock(&vcpu->kvm->mmu_lock);
if (mmu_notifier_retry(vcpu->kvm, mmu_seq))
goto out_unlock;
kvm_mmu_audit(vcpu, AUDIT_PRE_PAGE_FAULT);
if (make_mmu_pages_available(vcpu) < 0)
goto out_unlock;
if (!force_pt_level)
transparent_hugepage_adjust(vcpu, &walker.gfn, &pfn, &level);
/*写入HVA到页表*/
r = FNAME(fetch)(vcpu, addr, &walker, write_fault,
level, pfn, map_writable, prefault);
++vcpu->stat.pf_fixed;
kvm_mmu_audit(vcpu, AUDIT_POST_PAGE_FAULT);
}
对照前面的分析,比较容易理解这个函数了。首先是查guest的页表,如果从GVA到GPA的映射都没建立,那么返回,让Guest OS做这个工作。
然后,如果映射已经建立,GPA存在,那么从Guest的页面号,查找Host的页面号,try_async_pf函数根据GFN获取对应的PFN。从memslot可以知道user space首地址,就可以把物理地址GPA转为HVA,通过HVA就可以查到HPA,然后找到所在页的页号。
最后,写HVA到页表里面。页表在那里?回顾一下前面kvm_mmu_load的过程,页表是host申请的,host知道页表的真实物理地址。通过页表一层层的搜索,就可以找到要写入的页表项。
已知虚拟地址,一级级查找页表找到要写的页表项位置,是经常用的一种操作,这个函数可以认真分析一下实现过程。
IO虚拟化
IO虚拟化有两种方案,一种是半虚拟化方案,一种是全虚拟化方案。全虚拟化方案不需要修改Guest的代码,那么Guest里面的io操作最终都变成io指令。在前面的分析中,其实已经涉及了io虚拟化的流程。在VM-exit的时候,前文分析过page fault导致的退出。那么io指令,同样会导致VM-exit退出,然后kvm会把io交给Qemu进程处理。
而半虚拟化方案,基本都是把io变成了消息处理,从guest机器发消息出来,然后由host机器处理。此时,在guest机器的驱动都被接管。
Vmm对io的处理
当guest因为执行io执行退出后,由handle_io函数处理.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21arch/x86/kvm/vmx.c:
static int handle_io(struct kvm_vcpu *vcpu)
{
unsigned long exit_qualification;
int size, in, string;
unsigned port;
exit_qualification = vmcs_readl(EXIT_QUALIFICATION);
string = (exit_qualification & 16) != 0;
++vcpu->stat.io_exits;
if (string)
return kvm_emulate_instruction(vcpu, 0) == EMULATE_DONE;
port = exit_qualification >> 16;
size = (exit_qualification & 7) + 1;
in = (exit_qualification & 8) != 0;
return kvm_fast_pio(vcpu, size, port, in);
}
要从vmcs读退出的信息,然后调用kvm_fast_pio处理,最终走到真正的处理函数emulator_pio_in_out。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25arch/x86/kvm/x86.c:
tatic int emulator_pio_in_out(struct kvm_vcpu *vcpu, int size,
unsigned short port, void *val,
unsigned int count, bool in)
{
vcpu->arch.pio.port = port;
vcpu->arch.pio.in = in;
vcpu->arch.pio.count = count;
vcpu->arch.pio.size = size;
if (!kernel_pio(vcpu, vcpu->arch.pio_data)) {
vcpu->arch.pio.count = 0;
return 1;
}
/*要赋值退出的种种参数*/
vcpu->run->exit_reason = KVM_EXIT_IO;
vcpu->run->io.direction = in ? KVM_EXIT_IO_IN : KVM_EXIT_IO_OUT;
vcpu->run->io.size = size;
vcpu->run->io.data_offset = KVM_PIO_PAGE_OFFSET * PAGE_SIZE;
vcpu->run->io.count = count;
vcpu->run->io.port = port;
return 0;
}
这里要为io处理赋值各种参数,然后看内核能否处理这个io,如果内核能处理,就不用Qemu进程处理,否则退出内核态,返回用户态。
虚拟化io流程
从前文的分析中,我们知道返回是到Qemu的线程上下文中。实际上就是kvm_handle_io这个函数里面。
1 | kvm-all.c: |
然后调用每种设备所登记的指令处理函数处理,完成io。
各种设备都有自己的处理函数,所以Qemu需要支持各种不同的设备,Qemu的大部分代码都是各种各样设备的驱动代码(注意这里驱动的意义和传统驱动程序的含义有所不同)。
设备注册和设备模拟
QEMU设备注册可以移步qemu-qom详解
虚拟化概述脑图
脑图有待进一步完善
查看大图请点击这里

# 虚拟化 ## CPU虚拟化 ### 概述 #### 指令的模拟 ##### 陷入(利用处理器的保护机制,中断和异常) 1,基于处理器保护机制出发的异常 2,虚拟机主动触发的异常 3,异步zhognduan ###### 虚拟处理器 ###### 虚拟寄存器 ###### 上下文 #### 中断和异常的虚拟化 #### 对称对处理器技术的虚拟化(SMP) ##### VMM选择第一个虚拟处理器,BSP ##### 其他虚拟处理器,AP ### 主要函数 #### 创建VCPU ##### kvm_vm_ioctl_create_vcpu ###### kvm->created_vcpus++; ###### kvm_arch_vcpu_create ####### kvm_x86_ops->vcpu_create = vmx_create_vcpu ######## kvm_vcpu_init ######### kvm_arch_vcpu_init ########## kvm_mmu_create ########## kvm_create_lapic ###### kvm_arch_vcpu_setup ####### kvm_init_mmu ######## init_kvm_tdp_mmu ###### create_vcpu_fd #### 创建VM ##### kvm_dev_ioctl_create_vm ###### kvm_create_vm ####### kvm_arch_create_vm ######## kvm->mm = current->mm; ######## vmx_create_vcpu ######### vmx->guest_msrs = kmalloc(PAGE_SIZE, GFP_KERNEL); ######### vmx->host_msrs = kmalloc(PAGE_SIZE, GFP_KERNEL); ######### alloc_loaded_vmcs(&vmx->vmcs01); ######### alloc_apic_access_page ####### kvm_arch_vcpu_setup ######## vmcs_write64 ######## vmcs_write64 ####### kvm->mm = current->mm ####### kvm_eventfd_init #### VCPU运行 ##### kvm_arch_vcpu_ioctl_run ###### vcpu_run ####### vcpu_enter_guest ######## kvm_x86_ops->run(vcpu); ######### vmx_vcpu_run ########## asm(); ######## kvm_x86_ops->handle_external_intr(vcpu); ######## kvm_x86_ops->handle_exit(vcpu); ####### kvm_inject_pending_timer_irqs ####### kvm_vcpu_ready_for_interrupt_injection ######## exit_reason = KVM_EXIT_IRQ_WINDOW_OPEN ####### kvm_check_async_pf_completion #### 调度 ##### QEMU ###### qemu_kvm_start_vcpu ####### qemu_thread_create (cpu->thread, thread_name, qemu_kvm_cpu_thread_fn, cpu, QEMU_THREAD_JOINABLE); ######## kvm_cpu_exec ######### kvm_vcpu_ioctl(cpu, KVM_RUN, 0); ######### kvm_handle_io ######### address_space_rw #### 中断 ##### 中断注入 ###### vmx_inject_irq ####### vmcs_write32(VM_ENTRY_INTR_INFO_FIELD, intr); ##### 中断控制芯片模拟 ###### QEMU ####### kvm_irqchip_create ######## kvm_vm_ioctl(s, KVM_CREATE_IRQCHIP); ####### kvm_vm_ioctl(s, s->irq_set_ioctl, &event); ######## KVM_IRQ_LINE ####### qemu_cpu_kick_thread ######## err = pthread_kill(cpu->thread->thread, SIG_IPI); ####### kvm_set_irq ###### Kernel ####### kvm_vm_ioctl_irq_line ######## kvm_set_irq ######### kvm_pic_set_irq ######## kvm_pic_update_irq ######### pic_update_irq ########## kvm_vcpu_kick ########### send_ipi_message(cpumask_of(cpu), IPI_RESCHEDULE); ## Memory虚拟化 ### 概述 #### 内存地址连续 #### 物理地址从0开始 ### 主要函数 #### kvm_init_mmu ##### init_kvm_tdp_mmu ###### context->page_fault = tdp_page_fault; ####### mmu_topup_memory_caches ####### mapping_level ####### fast_page_fault ####### try_async_pf() ######## kvm_find_async_pf_gfn (PV) ######### yes: kvm_make_request(KVM_REQ_APF_HALT, vcpu); ######### no: kvm_arch_setup_async_pf(vcpu, gva, gfn) ########## kvm_setup_async_pf(vcpu, gva, kvm_vcpu_gfn_to_hva(vcpu, gfn), &arch) ########### INIT_WORK(&work->work, async_pf_execute); ########### kvm_inject_page_fault(vcpu, &fault); ####### __direct_map(vcpu, write, map_writable, level, gfn, pfn, prefault); ######## for_each_shadow_entry(vcpu, (u64)gfn << PAGE_SHIFT, iterator) ######## kvm_mmu_get_page ######### for_each_gfn_sp ######### kvm_mmu_alloc_page(vcpu, parent_pte, direct); ########## mmu_memory_cache_alloc(&vcpu->arch.mmu_page_header_cache) ########## mmu_memory_cache_alloc(&vcpu->arch.mmu_page_cache); ######## link_shadow_page ###### context->root_level = is_la57_mode(vcpu) ?PT64_ROOT_5LEVEL : PT64_ROOT_4LEVEL; ##### init_kvm_softmmu ###### kvm_init_shadow_mmu ####### paging64_init_context ######## paging64_init_context_common ######### paging64_page_fault ########## FNAME(page_fault) ########### inject_page_fault ########### try_async_pf ########### FNAME(fetch) #### kvm_mmu_reload ##### kvm_mmu_load ###### mmu_alloc_roots ###### kvm_mmu_load_cr3 #### __kvm_set_memory_region ##### new.userspace_addr = mem->userspace_addr ##### kvzalloc(sizeof(struct kvm_memslots), GFP_KERNEL); #### handle_exception ##### intr_info = vmx->exit_intr_info; ##### kvm_mmu_page_fault ## I/O虚拟化 ### 概述 #### 设备发现 ##### 总线类型的设备 ###### 总线类型不可枚举 ####### ISA设备 ####### PS/2键盘、鼠标、RTC ####### 传统IDE控制器 ###### 总线类型可枚举、资源可配置 ####### PCI ##### 完全模拟的设备 ###### Frontend / backend 模型 #### 访问截获 ##### I/O端口的访问 ###### I/O位图来决定 ##### MMIO访问 ###### 页表项设置为无效 #### 设备模拟 ### 主要函数 #### PIO ##### handle_io ###### emulator_pio_in_out ####### kernel_pio ##### kvm_handle_io ###### address_space_rw #### MMIO ##### vmx_enable_tdp ###### ept_set_mmio_spte_mask ####### kvm_mmu_set_mmio_spte_mask(, 110b) an EPT paging-structure entry is 110b (write/execute). ##### vcpu_run/entry_guest之后 ###### vm_exit//tdp_page_fault ####### kvm_check_async_pf_completion ######## kvm_arch_async_page_ready ######### context->page_fault = tdp_page_fault ########## __direct_map / 构建EPT ########### mmu_set_spte ############ if (unlikely(is_noslot_pfn(pfn))) mark_mmio_spte(vcpu, sptep, gfn, access); ##### handle_ept_misconfig ###### kvm_mmu_page_fault ####### ++vcpu->stat.mmio_exits; return 1; //Qemu process first ## 中断虚拟化 ### 概述 #### Local APIC per VCPU ##### 虚拟PIC (i8259) ##### 虚拟IO-APIC ##### 虚拟Local APIC #### 中断采集 #### 中断注入 ### 主要函数 #### IOCTL (KVM_CREATE_IRQCHIP) ##### kvm_pic_init ###### kvm_io_bus_register_dev(kvm, KVM_PIO_BUS ###### kvm->arch.vpic ##### kvm_ioapic_init ###### kvm_io_bus_register_dev(kvm, KVM_MMIO_BUS, ioapic->base_address, ###### kvm->arch.vioapic ##### kvm_setup_default_irq_routing ###### kvm_set_irq_routing(kvm, default_routing, ####### setup_routing_entry #### 虚拟设备中断 ##### IOCTL(KVM_IRQ_LINE)中断注入 ###### kvm_set_irq irq_set[i].set( ####### kvm_set_pic_irq ######## kvm_vcpu_kick ####### kvm_set_ioapic_irq ######## ioapic_service ######### kvm_irq_delivery_to_apic ########## kvm_apic_set_irq ########### kvm_make_request ########### kvm_vcpu_kick ###### vcpu_enter_guest / guest_run之前! ####### inject_pending_event ######## kvm_x86_ops->set_irq(vcpu); ######### vmx_inject_irq ########## vmcs_write32(VM_ENTRY_INTR_INFO_FIELD, intr); #### 外部设备中断 external interrupt ##### vcpu_enter_guest ###### kvm_x86_ops->handle_external_intr ####### vmx_handle_external_intr ######## vector = exit_intr_info & INTR_INFO_VECTOR_MASK ######## 直接把vector送给host上的中断handler ### LAPIC 虚拟化 #### alloc_apic_access_page #### page = gfn_to_page(kvm, 0xfee00 000) ##### vmcs_write64(VIRTUAL_APIC_PAGE_ADDR, __pa(vmx->vcpu.arch.apic->regs)) ##### vmcs_write64(APIC_ACCESS_ADDR, page_to_phys(vmx->vcpu.kvm->arch.apic_access_page));
调用关系图
Perf 简介
补充一个可以获取内核函数间动态调用关系图(call graph)的方法。很简单借助内核中,一个功能强大的工具软件perf。通常用户可以通过apt之类的工具从系统的源内安装,但如果自己升级过内核,那就需要自己编译安装下了,并不复杂:1
2cd <kernel source code>
cd tools/perf/ && make && make install
Perf是一个动态代码统计工具。它通过每秒钟多次中断或采样运行中的软件程序,所以能够知道软件里正在发生着什么,但并没有很影响软件的运行速度。
在采样中,perf会看到函数调用栈(call stack),来进行分析。当然perf还有其他很多功能,另外perf还有一个UI可以使用,KCacheGrind,这里不赘述了。
perf中关于call-graph 的参数这里简单介绍几个:
1 | --call-graph=graph: use a graph tree, displaying absolute overhead rates. |
Perf 搭建
在使用Perf之前,需要确认系统中是否支持perf:
1 | $ perf record |
如果遇到上面的错误,在文件/etc/sysctl.conf中添加kernel.perf_event_paranoid = -1。然后重启系统或者,运行sudo sysctl --system加载配置。
Perf 运行
1 | perf record -a --call-graph dwarf /home/works/crosvm_kvm/crosvm/src/platform/crosvm/target/debug/crosvm run --disable-sandbox --cpus 4 --mem 4096 --rwdisk=/home/works/kvm/ubuntu20.10_rootfs.img --params=root=/dev/vda3 --socket=/tmp/crosvm.sock /home/works/crosvm_kvm/vmlinuz-5.11.0-intel-next-adl-alpha-rc1 |
上面只是一个例子,运行perf record -a --call-graph dwarf <Your app with args> 所有的参数都写在同一行上。
这样会在程序运行的同时,在当前目录生成一个文件perf.data,注意这个文件会非常大,控制程序运行时间。然后退出程序,或者Ctrl+C 杀掉进程,之后运行perf report就可以看到call trace了,当然是terminal 文字的树状图。
1 | perf --call-graph=0.5 to filter out all calls whose cost is below 0.5%. I usually use perf --call-graph=1 to filter out the noise I don't care about |
效果如图: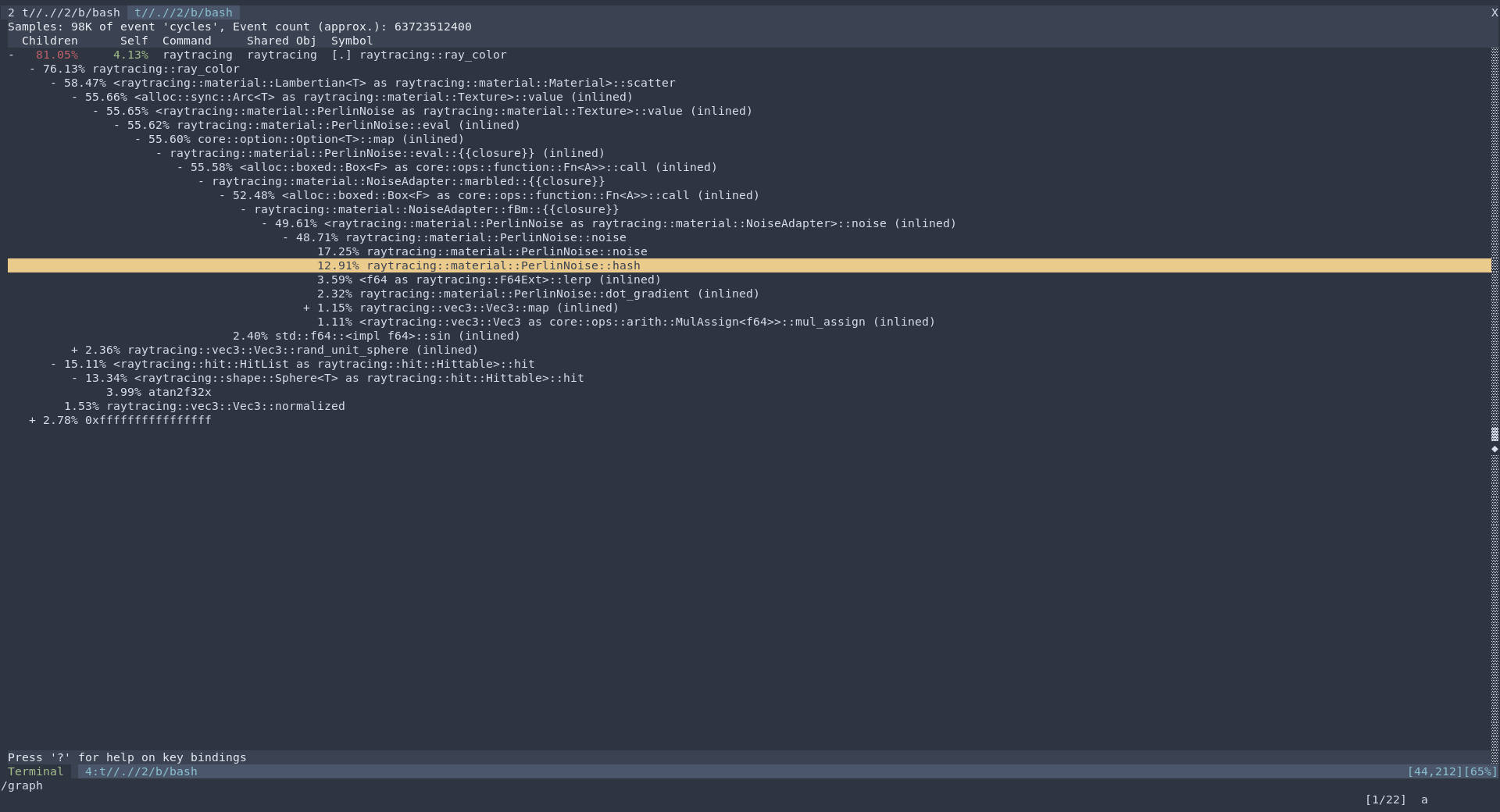


{kind=link}