浅谈“内存读写重排序”
在我们编写C/C++代码时,以及它在CPU上运行时,按照一些规则,代码中原有的内存读写指令的执行顺序(又叫“程序顺序”, program ordering)会被重新排列。这个现象会在两个地方引入,编译时候由编译器引入;以及运行时由处理器引入。目的都是为了”使代码运行的更快”。尽管本文重在说明运行时CPU对内存读写的重排序作用。但考虑完整性以及防止读者混淆,我们会两种重排序一起介绍。
1 | c_code=>operation: C 语言 |
X86的内存读写顺序模型
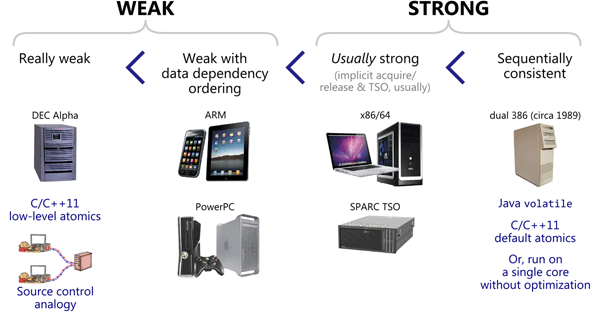
按照内存访问重排序发生情况的多少,大概划分为下面三种“顺序模型”。
弱顺序模型
弱顺序模型中,可能会出现四种内存重排序(Load-Load, Store-Store, Load-Store 和 Store-Load)。任意读(load)操作和写(store)操作都有可能与其他读写操作重排序,只要它能保证原来程序的行为。采用弱顺序模型的处理器可以称为“weakly-order”或者”weak ordering”。
对于C/C++的编译器gcc(因为我只用过gcc:p),都可以呈现弱顺序模型,稍后我们看下例子。
强顺序模型
强顺序模型和弱顺序模型的界限可能不一定有确切的标准,但从SDM 8.2章开头可以看到,奔腾4之后的X86处理器大概属于强顺序类型:
To allow performance optimization of instruction execution, the IA-32 architecture allows departures from strongordering model called processor ordering in Pentium 4, Intel Xeon, and P6 family processors
继续读SDM8.2 可以发现如下约定:
- Reads are not reordered with other reads. (任何‘读-读’之间不可重排序)
这就意味着前述弱顺序模型中的重排序中的”load-load”禁止。 - Writes are not reordered with older reads. (‘写’不可向前重排到‘读’之前)
这就意味着弱顺序模型中的”load-store”被禁止。 - Writes to memory are not reordered with other writes, with the following exceptions:… (‘写’与‘写’之间不可以重排序,但除了如下例外。例外的部分我们暂时忽略)
这就意味着弱顺序模型中的大部分”store-store”是被禁止的,例外情况文末会提到。 - Reads may be reordered with older writes to different locations but not with older writes to the same location. (‘读’可以向前重排序到不同内存位置的‘写’之前)
这就明确的说明4种弱顺序模型中的store-load是被允许的!。这也是我们后面实例的重要依据。
顺序一致
所有运行时内存访问的顺序跟程序顺序一模一样。现如今都是多核系统,可能很难找到可以成为顺序一致(Sequential consistency)的CPU了。如果真要追溯可能是386时代。
编译时内存顺序重排序
我们先通过下面这个最简单的实例,体验编译器如何进行内存访问的重排序的,直接看代码:1
2
3
4
5int a, b;
void test() {
a = b;
b = 1;
}
写了一个.c 文件,里面仅仅包含了上面这几行,然后我们用gcc把它翻译成汇编语言:
1 | $gcc -S -O0 test.c -o test1.s |
1 | $gcc -S -O2 test.c -o test2.s |
通过这个例子可以明显的感受到gcc的弱顺序模型:-O0的时候,顺序跟我们预期的程序顺序是一致的;但当使用-O2优化时,test函数的最后一句的变量b赋值明显已经被向前重排到了变量a的存储之前!
但我们需要知道的是,这样的重排序,对于单线程的硬件来说,重排序并不会影响程序最后的执行结果。但是对于多线程来说,如果有另外的线程实时的读取变量a的值的话,很可能会得到错误的结果。
如何阻止编译器的重排序?
前辈们习惯的用法是这样的:1
2
3
4
5
6int a, b;
void test() {
a = b;
asm volatile("" ::: "memory");
b = 1;
}
加了嵌入式汇编asm volatile("" ::: "memory");后的test.c再无论怎么优化,都会得到跟-O0一样的汇编结果。
CPU运行时重排序
前面的一篇文章大概翻译了下SDM的8.2章节SMD Chapter 8.2 内存存取顺序,我们按照SDM8.2.3.4的描述,重现一个store-read操作的重排序,并且观察MFENCE是如何工作的,以保证执行顺序的正确。
回顾SDM8.2.3.4的内容
intel-64存取顺序重排允许加载操作重排序到不同地址的存储之前,但不允许重排序到同一个地址的存储之前。
| 处理器0 | 处理器1 |
|---|---|
| mov [x],1 | mov [y],1 |
| mov r1 [y] | mov r2,[x] |
| 初始值 x=y=0 | |
| r1 = 0 并且 r2 = 0 允许 |
代码实现
下面我们就来实现上面这段逻辑:
1 | #define USE_CPU_FENCE 0 |
完整的可编译的code可以到github上clone:git clone -b memory_ordering https://github.com/ysun/acrn-unit-test.git
在guest文件夹里执行make unit file=memory_order就可以执行了。
源码分析
读代码难免有点枯燥,我们把流程图画一下就一目了然了:
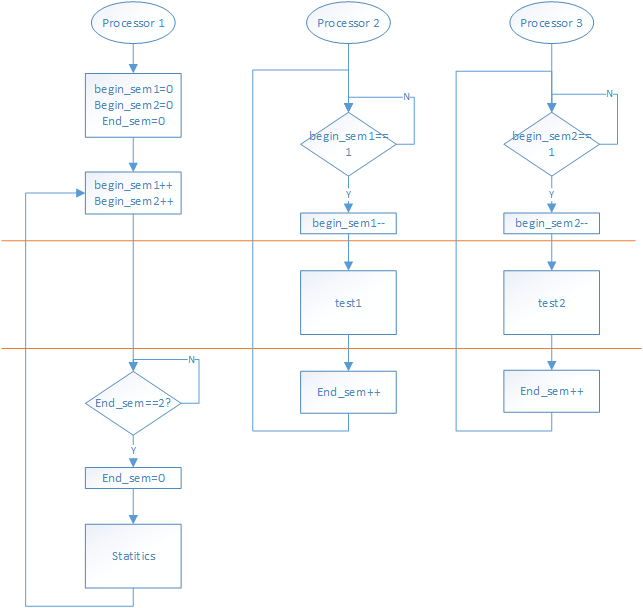
上面这个例子中一共涉及到了三个逻辑CPU(core)。BSP(processor1)就是上电后第一个执行指令的逻辑CPU,负责另外两个AP(processor2和processor3)的同步工作。两个AP负责分别运行两段测试代码
test1和test2。程序一开始,两个AP(processor2和processor3)忙等待BSP发来的同步信号(begin_sem1和begin_sem2)。BSP在进行了必要的初始化操作之后,使用原子操作(atomic_inc)分别将上述两个信号 +1。两个AP等到各自的信号之后,立即清除该信号,然后准备测试。
所以,我们可以认为processor2和processor3几乎是同步运行的。也就是test1和test2代码块可以认为是同时运行。此时processor1在忙等待两个AP的测试完成end_sem == 2。
test1和test2的两段汇编很简单,严格按照前面的表各种所述。如果没有重排序的发生,那么两个寄存器变量中r1和r2中的值都应该是1。但如果我们发现某次test1和test2测试结束后,r1和r2的值同时为0的时候,那么就说明发生了重排序,test1和test2中的两个store操作,也就是
movl %2, %0这句重排到了movl $1, %1这句之前,而且是两个processor同时发生这样的重排序。processor1在end_sem == 2的时候,意味着两个AP都已完成,此时processor1检测是否r1 == r2 == 0。
通过改变宏定义USE_CPU_FENCE 的值来重现重排序,以及引入MFENCE来防止重排序。
执行结果
下面两个图就是义USE_CPU_FENCE=0和USE_CPU_FENCE=1两次不同的运行结果。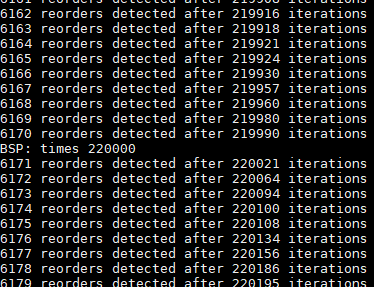
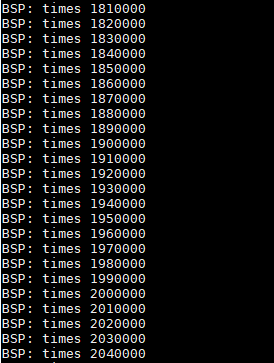
从打印的日志可以容易的看出图一发生了重排序,图二中大概200w次测试没有发生重排序。需要指出的是这里200w次循环执行时间不超过1秒钟,非常快。
LFENCE 和 SFENCE
既然说到FNECE了,咱就得讲完另外两种LFENE和SFENCE。SDM里面讲LFENCE是保证load-load操作不被重排序,SFENCE是保证store-store不被重排序,就是前面在说SDM8.2里面列举了禁止的弱顺序模型中的store-store我们省略掉的部分。
Writes to memory are not reordered with other writes, with the following exceptions:
— streaming stores (writes) executed with the non-temporal move instructions (MOVNTI, MOVNTQ,
MOVNTDQ, MOVNTPS, and MOVNTPD); and
— string operations (see Section 8.2.4.1)
这里我利用RDTSC指令实现了LFENCE组织CPU指令的重排序,这里不列举了,大概意思是,在一个逻辑CPU上,利用两次rdtsc指令之间插入LFENCE来观察循环的周期的长短来判断LFENCE的作用。只放个链接在这里吧memory_ordering_lfence.c
但对于SFENCE,我按照SDM 8.2.2所述内容并没有重现MOVNTI指令的store-store重排序,所以没能确认SFENCE的作用。
我的MOVNTI和SFENCE的测试代码在这里memory_ordering_sfence.c,幻想着某位大牛可以回复我一下!!!
参考文档:
https://preshing.com/20120930/weak-vs-strong-memory-models/
https://preshing.com/20120515/memory-reordering-caught-in-the-act/
http://dreamrunner.org/blog/2014/06/28/qian-tan-memory-reordering/

