GCC汇编语法梗概
AT&T 与 Intel 汇编区别
Linux GCC(GNU, C Compiler)使用AT&T汇编语法。下面列一下AT&T 和Intel汇编语法中的不同:
源-目的 顺序
AT&T中源和目的操作数的顺序相反。Intel语法中第一个操作数是目的,第二个是源。而AT&T语法中,第一个是源第二个操作数是目的。
“Op-code src, dst” —— AT&T 语法
“Op-code dst, src” —— Intel语法
寄存器命名
AT&T语法中,寄存器需要有‘%’前缀,例如eax需要写作%eax。这里只是强调Intel汇编语法中不使用各种前缀,具体寄存器命名后面会继续涉及。
立即数
AT&T中立即数需要有‘$’前缀。如果是静态“C”变量,同样需要’$’前缀。
Intel语法中,16进制需要’h’前缀,而AT&T则需要‘0x’前缀。所以,对于16进制的立即数写作 ‘$0x1234’
操作数大小
在AT&T语法中,内存操作数的大小取决于Op-code的后缀字母’b’’w’以及’l’,分别指代’字节(8bit) 字(16bit) 和长字(32bit)内存指针。而Intel语法使用前置限定符’byte ptr’ ‘word ptr’ 以及’dword prt’。
所以下面两句等效:1
2Intel "mov al, byte ptr foo"
At&T "movb foo, %al"
内存地址的访问
在AT&T中基址寄存器使用’()’,Intel中使用’[]’。 下面两句等效:1
2Intel "section: [base + index*scale + disp]"
AT&T "section: disp(base, index, scale)"
GNU AT&T汇编
寄存器
现代X86处理器(例如386及其以后)有8个32位通用寄存器(general purpose registers,GPR)如图: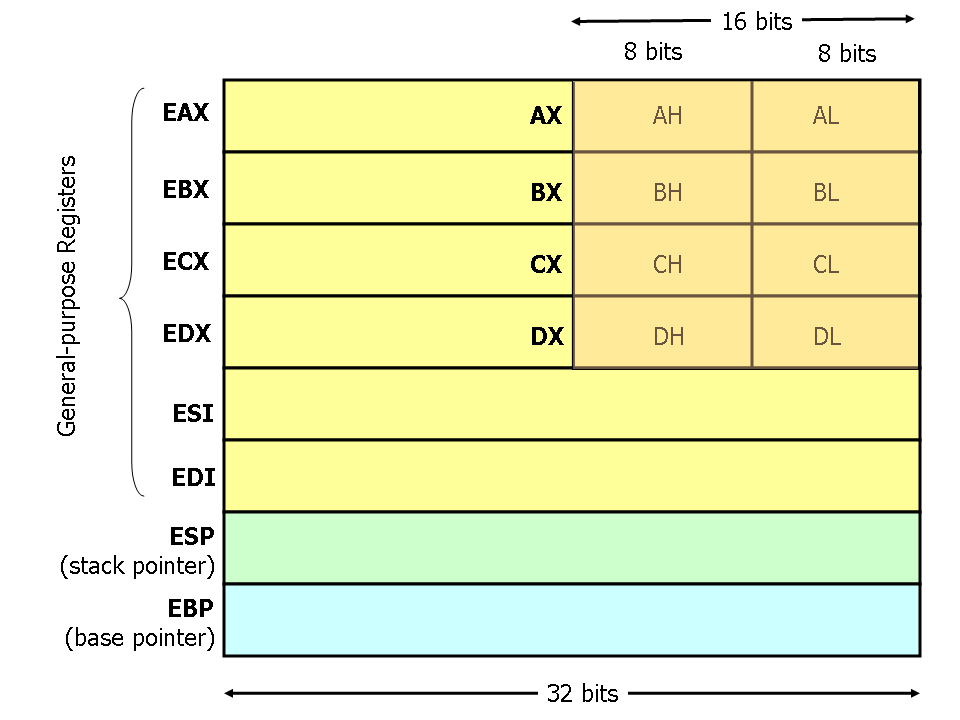
寄存器名字是继承过来的。例如EAX成为累加器,因为之前被大量的算法这样操作,ECX被称为计数器,因为它通常用来作为循环的索引。然而,在现代指令集中,大多数寄存器已经失去了它之前特殊的用途。但有两个例外的——堆指针(ESP)和基址指针(EBP)。
对于EAX EBX ECX以及EDX,可以分段使用。例如,EAX的低2字节可以看做是16位寄存器,称作AX;低1字节可以看做8位寄存器,称作AL,而AX的高字节也可以看作是8位寄存器,成为AH。这些寄存器名字都指向相同的物理寄存器。当2字节数值存入DX中的时候,它会影响DH,DL以及EDX。1
2
3
4movb $2, (%ebx) /* Move 2 into the single byte at the address stored in EBX. */
movw $2, (%ebx) /* Move the 16-bit integer representation of 2 into the 2 bytes starting at the address in EBX. */
movl $2, (%ebx) /* Move the 32-bit integer representation of 2 into the 4 bytes starting at the address in EBX. */
内存操作符
X86指令中,我们可以生命静态数据区域(类似全局变量)。使用.data指令来声明,紧跟在.data指令之后,使用指令.byte, .short 以及.long来声明1,2或者4字节数据位置,然后使用标签来引用之前创建的数据区。标签可以看做是内存区域的名字,可以在之后的汇编或者连接器中使用标签,这就跟用名字声明变量非常的相似,但稍微有些不同。比如,一个连续的内存数据位置的声明他们在内存中的位置是连续的。1
2
3
4
5
6
7
8
9.data
var:
.byte 64 /* Declare a byte, referred to as location var, containing the value 64. */
.byte 10 /* Declare a byte with no label, containing the value 10. Its location is var + 1. */
x:
.short 42 /* Declare a 2-byte value initialized to 42, referred to as location x. */
y:
.long 30000 /* Declare a 4-byte value, referred to as location y, initialized to 30000. */
并不像高级语言那样,数组可以有各种容量,并且可以使用索引访问。X86汇编中的数组仅仅是简单的一些内存中接续的存储单元。数组可以通过列出数值累声明(例如第一个例子)。对于一些特别的数组,可以使用字符串;再如果一个很大的内存需要填充0,那么可使用.zero指令。1
2
3
4
5
6
7
8
9s:
.long 1, 2, 3 /* Declare three 4-byte values, initialized to 1, 2, and 3.
The value at location s + 8 will be 3. */
barr:
.zero 10 /* Declare 10 bytes starting at location barr, initialized to 0. */
str:
.string "hello" /* Declare 6 bytes starting at the address str initialized to
the ASCII character values for hello followed by a nul (0) byte. */
内存寻址
现代X86处理器最高可寻址2^32字节的内存地址(内存地址有32位宽)。上面的例子中,我们使用标签指向内存区域,这些标签实际上被编译器用实际32位地址取代。为了更进一步支持标签指向内存地址(例如常量),X86提供了一个灵活的计算和引用内存地址的方法:两个32位寄存器以及一个32位有符号常量相加,并且其中一个寄存器可以被2,4,8相乘。
有一点需要注意,当disp/scale中使用常数的时候,这里不再需要”$”前缀。
| Intel 代码 | AT&T 代码 |
|---|---|
| mov eax, 1 | movl $1, %eax |
| mov ebx, 0ffh | movl $0xff, %ebx |
| int 80h | int $0x80 |
| mov ebx, eax | mov %eax, %ebx |
| mov eax, [ecx] | movl (%ecx), %eax |
| mov eax, [ebx + 3] | movl 3(%ebx), %eax |
| mov eax, [ebx + 20h] | movl 0x20(%ebx), %eax |
| mov eax, [ebx + ecx] | movl (%ebx,%ecx), %eax |
| mov eax, [ebx + ecx*2h] | movl (%ebx,%ecx,0x2), %eax |
| mov eax, [ebx + ecx*4h-20h] | movl -0x20(%ebx,%ecx,0x4), %eax |
基本内联
基本内联汇编的格式比较简单:1
asm("assembly code");
例如:1
2asm("movl %ecx, %eax"); //把ecx中的内容移动到eax中
__asm__("movb %bh, (%eax)") //把寄存器bh中的内容移动到eax指向的内存地址
这里有几点注意事项:
- 千万不要忘记src, dst两个操作数之间的逗号’,’
- 这里
asm()和__asm()__都是有效的。 - 如果有多行汇编,需要在每行末尾添加
\n\t,除最后一行汇编的末尾。例如:
1 | __asm__ ("movl %eax, %ebx \n\t" |
如果在代码中,更改过一些寄存器并从asm返回后,则会发生一些难以预料的事情。这是因为GCC不知道寄存器内容的变化,所致,特别是当编译器进行一些优化时。这就需要一些扩展功能的地方。下面来看下扩展的asm语法。
扩展的ASM
在基本内联汇编中,我们只有指令。但在扩展汇编中,我们可以指定操作数。并且允许指定输入寄存器,输出寄存器以及改动的寄存器列表。但不强制使用寄存器。格式如下:1
2
3
4
5asm ( assembler template
: output operands /* optional */
: input operands /* optional */
: list of clobbered registers /* optional */
);
如果没有输出操作符,但有输入操作,也必须保留两个冒号,例如:1
2
3
4
5
6
7asm ("cld \n\t" //多行指令
"rep \n\t"
"stosl"
: /* 没有输出寄存器 */
: "c" (count), "a" (fill_value), "D" (dest)
: "%ecx", "%edi"
);
上段代码意思是,把fill_value变量中的值往edi指向的内存地址写入count次。也就是说,eax和edi中的内容不再有效。再来看下面的例子:1
2
3
4
5
6
7int a=10, b;
asm ("movl %1, %%eax; \n\t"
"movl %%eax, %0;"
:"=r"(b) /* output */
:"r"(a) /* input */
:"%eax" /* clobbered register */
);
这段代码意思是,把变量a的值赋值给b。
- ‘b’是输出操作符,%0引用它,并且’a’是输入操作符,1%引用它。
- ‘r’是操作符的限定符。这里’r’告诉GCC可以使用任意一个寄存器来存储操作符。’=’是输出操作符的限定符,并且是只写的。
- 在寄存器之前有两个’%’号。用来帮助GCC区别操作符还是寄存器。操作符只有一个’%’前缀。
换句话说,在扩展ASM语法中,如果在汇编中直接使用寄存器名字而不是通过%0 %1这样引用,则寄存器前需要两个%限定。 - 改动的寄存器%eax列在第三个冒号在后,告诉GCC %eax的值在汇编中有改动,所以GCC不会再用这个寄存器存储其他的值。
当asm结束时,’b’会反应更新过的数据,因为他被指定为输出操作符。换句话说,在汇编中改变’b’的值,会被反映到汇编之外。 - 但如果一个寄存器已经出现在输出操作符列表中,那么无需再将它添加到clobber list里,如果添加了编译的时候会报错。例如下面这段汇编是错误的:
1
2
3
4
5
6
7int a=10, b;
asm ("movl %1, %%eax; \n\t"
"movl %%eax, %0;"
:"=b"(b) /* 明确指出使用寄存器ebx */
:"r"(a) /* input */
:"%eax", "%ebx" /* 编译出错!! */
);
编译器模板
操作数
每个 操作数都必须包含在“”之内。对于输出操作数,双引号(“”)中会多一个限定符,用来决定限定符地址的模式。
如果有多个操作数,他们使用逗号(,)隔开。
每个操作数都可以通过数字来引用,按照顺序一次命名。输入和输出操作数依次命名,第一个输出的操作数记作0,后面依次增加。
输出操作数必须是长类型,输入操作数没有这个限制。扩展汇编最常用来调用机器指令本身,跟编译器无关。如果输出表达式不是一个直接地址,例如一个位阈,限定符必须是寄存器。此事,GCC会使用寄存器作为内联汇编的输出,并且把寄存器的值存储到输出里。
综上,原始输出操作数必须是“只写”的;GCC假定在指令结束之前,数值都在这些操作数中,并且不需要生成。扩展汇编也支持读写操作数。
来看几个例子:1
2
3
4asm ("leal (%1, %1, 4), %0"
: "=r" (five_times_x)
: "r" (x)
);
这个例子中,输入是’x’,并且没有指定寄存器。GCC会自己选择一个。再同样给输出选择一个寄存器。如果我们想要输入输出使用同一个寄存器,可以告诉GCC我们希望那种读写的操作数,比如:1
2
3
4asm ("leal (%0, %0, 4), %0"
: "=r" (five_times_x)
: "0" (x)
);
此时,输入输出操作数会是同一个寄存器。但我们并不知道是具体那一个。如果想明确指定某一个寄存器,也有方法,比如:1
2
3
4asm ("leal (%%ecx,%%ecx,4), %%ecx"
: "=c" (x)
: "c" (x)
);
以上三个例子,并没有指定任何改动寄存器列表,为什么?前两个例子,GCC决定使用哪个寄存器,它会知道寄存器发生的变化。在最后一个例子中,我们也没有指定变化寄存器,因为GCC知道值最终保存到x中,在汇编之外,它知道ecx的值了,所以没有必要列出变化寄存器列表(clobber list),如果列上%ecx编译就会错误。
变化寄存器列表(clobber)
有些指令会改变硬件寄存器,因此必须明确指出这些改动过的寄存器,将其列在第三个’:’之后。这是为了告诉GCC汇编使用并修改了那些寄存器。所以,GCC会知道之前被加载到这些寄存器的值已经无效了。同时没有必要列出放在输入和输出操作数中的寄存器,以内GCC知道内联已经使用了他们。需要明确指出的是那些没有明确指出的隐式使用的寄存器,那些没有列在输入和输出操作数中的寄存器。
如果指令修改了内存,需要在clobber list中添加”memory”。这样通知GCC内存缓存应该失效了。同时必须添加’volatile’关键字,如果内存修改并没有列在输入和输出操作数中时。
我们多次可以读写更改的寄存器,参考下面的例子,意思是调用子程序_foo,并且通过eax 和 ecx传递两个参数给他。
注:这里的寄存器名字前是否加%,eax和%eax都是正确的!1
2
3
4
5
6
7asm ("movl %0,%%eax; \n\t"
"movl %1,%%ecx; \n\t"
"call _foo"
: /* no outputs */
: "g" (from), "g" (to)
: "eax", "ecx"
);
Volatile 关键字
如果熟悉内核源码,我们会经常看到volatile或者volatile关键字在 asm或者asm之后。
如果内联汇编需要在它原来所在的位置处被执行,例如不被移到循环的外面或者不被优化掉,在asm 和 ()之间放一个volatile,像这样:1
asm volatile ( ... : ... : ... : ...);
如果我们添加的汇编语言仅仅是为了计算并且没有任何边际效应,最好不要使用volatile关键字,因为volatile会妨碍代码优化。
关于限定符
前面的例子中我们已经使用了很多限定符,但还没有具体讲限定符的作用。限定符可以规定操作数是否在寄存器中,什么样的寄存器;以及操作数是指向内存以及内存地址类型;操作数是否是立即数,和数字的范围。来看下常用的限定符。
寄存器操作数限定符 ‘r’
当使用这个限定符时,操作数被存储在通用寄存器中(General Purpose Registers, GPR)。举例说明:1
asm ("movl %%eax, %0\n" :"=r"(myval));
变量myval被存储到及粗糙那其中,寄存器eax中的值被copy到那个寄存器中,并且myval的值会被从寄存器更新到内存中。因为限定符’r’,gcc会把变量保存到任何一个通用寄存器中。如果需要明确指定某一个寄存器,需要使用相对应的限定符,如下表:
| r | GPRs |
|---|---|
| a | %eax, %ax, %al |
| b | %ebx, %bx, %bl |
| c | %ecx, %cx, %cl |
| d | %edx, %dx, %dl |
| S | %esi, %si |
| D | %edi, %di |
内存操作数限定符 ‘m’
当操作数在内存中,任何关于操作数的操作都直接访问内存地址。相反,寄存器操作数是先把数据存储到寄存器中,在写回到内存地址中。但寄存器限定符只有当指令明确需要或者明显加速处理,才会存储到寄存器中。当一个C变量需要在内联汇编更新的时候,内存限定符会更方便,并且,我们并不是真的需要用寄存器来存储值。例如存储IDTR的值到loc中:1
asm("sidt %0\n" : :"m"(loc));
匹配限定符(Digit)
很多情况下,一个变量就可以做输入也可以做输出操作数,例如:1
asm ("incl %0" :"=a"(var):"0"(var));
来看一个简单的例子,寄存器eax及用作输入同时用作输出操作数。变量var作为输入,传值给eax,并且在完成自增后,又更新到eax中。“0”这里指代同一个限定符,第0个,也就是输出变量。也就是输出变量var只会被存到eax中。通常下列情况可以这样使用:
- 当变量作为输入,并且协会到同一个变量中。
- 没必要把输入和输出分开的时候。
匹配限定符最重要的作用是高效的使用寄存器。
其他限定符:
“g” : Any register, memory or immediate integer operand is allowed, except for registers that are not general registers.
“m” : A memory operand is allowed, with any kind of address that the machine supports in general.
“o” : A memory operand is allowed, but only if the address is offsettable. ie, adding a small offset to the address gives a valid address.
“V” : A memory operand that is not offsettable. In other words, anything that would fit the m’ constraint but not theo’constraint.
“i” : An immediate integer operand (one with constant value) is allowed. This includes symbolic constants whose values will be known only at assembly time.
“n” : An immediate integer operand with a known numeric value is allowed. Many systems cannot support assembly-time constants for operands less than a word wide. Constraints for these operands should use ’n’ rather than ’i’.
下面是X86特有的限定符:
“r” : Register operand constraint, look table given above.
“q” : Registers a, b, c or d.
“I” : Constant in range 0 to 31 (for 32-bit shifts).
“J” : Constant in range 0 to 63 (for 64-bit shifts).
“K” : 0xff.
“L” : 0xffff.
“M” : 0, 1, 2, or 3 (shifts for lea instruction).
“N” : Constant in range 0 to 255 (for out instruction).
“f” : Floating point register
“t” : First (top of stack) floating point register
“u” : Second floating point register
“A” : Specifies the ‘a’ or ‘d’ registers. This is primarily useful for 64-bit integer values intended to be returned with the ‘d’ register holding the most significant bits and the ‘a’ register holding the least significant bits.
限定修饰符
- ‘=’ 意思是操作数是“只写”的,之前的值会被输出值覆盖掉。
- ‘&’ 意思是输入操作数在本条指令完成之前,被修改。但这个操作数可能没有列在输入操作数列表或者是内存的一部分。如果输入仅仅用于早起结果的输入时,输入操作数可以被看做earlyclobber操作数
- ‘+’ 意思是操作数是“可读可写”的。
参考:https://gcc.gnu.org/onlinedocs/gcc/Extended-Asm.html
https://www.ibm.com/developerworks/cn/linux/sdk/assemble/inline/
http://flint.cs.yale.edu/cs421/papers/x86-asm/asm.html
实例
First we start with a simple example. We’ll write a program to add two numbers.
1 | int main(void) |
Here we insist GCC to store foo in %eax, bar in %ebx and we also want the result in %eax. The ’=’ sign shows that it is an output register. Now we can add an integer to a variable in some other way.
1 | __asm__ __volatile__( |
This is an atomic addition. We can remove the instruction ’lock’ to remove the atomicity. In the output field, “=m” says that my_var is an output and it is in memory. Similarly, “ir” says that, my_int is an integer and should reside in some register (recall the table we saw above). No registers are in the clobber list.
Now we’ll perform some action on some registers/variables and compare the value.
1 | __asm__ __volatile__( "decl %0; sete %1" |
Here, the value of my_var is decremented by one and if the resulting value is 0 then, the variable cond is set. We can add atomicity by adding an instruction “lock;\n\t” as the first instruction in assembler template.
In a similar way we can use “incl %0” instead of “decl %0”, so as to increment my_var.
Points to note here are that (i) my_var is a variable residing in memory. (ii) cond is in any of the registers eax, ebx, ecx and edx. The constraint “=q” guarantees it. (iii) And we can see that memory is there in the clobber list. ie, the code is changing the contents of memory.
How to set/clear a bit in a register? As next recipe, we are going to see it.
1 | __asm__ __volatile__( "btsl %1,%0" |
Here, the bit at the position ’pos’ of variable at ADDR ( a memory variable ) is set to 1 We can use ’btrl’ for ’btsl’ to clear the bit. The constraint “Ir” of pos says that, pos is in a register, and it’s value ranges from 0-31 (x86 dependant constraint). ie, we can set/clear any bit from 0th to 31st of the variable at ADDR. As the condition codes will be changed, we are adding “cc” to clobberlist.
Now we look at some more complicated but useful function. String copy.1
2
3
4
5
6
7
8
9
10
11
12 static inline char * strcpy(char * dest,const char *src)
{
int d0, d1, d2;
__asm__ __volatile__( "1:\tlodsb\n\t"
"stosb\n\t"
"testb %%al,%%al\n\t"
"jne 1b"
: "=&S" (d0), "=&D" (d1), "=&a" (d2)
: "0" (src),"1" (dest)
: "memory");
return dest;
}
The source address is stored in esi, destination in edi, and then starts the copy, when we reach at 0, copying is complete. Constraints “&S”, “&D”, “&a” say that the registers esi, edi and eax are early clobber registers, ie, their contents will change before the completion of the function. Here also it’s clear that why memory is in clobberlist.
We can see a similar function which moves a block of double words. Notice that the function is declared as a macro.1
2
3
4
5
6
7
8
9 #define mov_blk(src, dest, numwords) \
__asm__ __volatile__ ( \
"cld\n\t" \
"rep\n\t" \
"movsl" \
: \
: "S" (src), "D" (dest), "c" (numwords) \
: "%ecx", "%esi", "%edi" \
)
Here we have no outputs, so the changes that happen to the contents of the registers ecx, esi and edi are side effects of the block movement. So we have to add them to the clobber list.
In Linux, system calls are implemented using GCC inline assembly. Let us look how a system call is implemented. All the system calls are written as macros (linux/unistd.h). For example, a system call with three arguments is defined as a macro as shown below.1
2
3
4
5
6
7
8
9
10 #define _syscall3(type,name,type1,arg1,type2,arg2,type3,arg3) \
type name(type1 arg1,type2 arg2,type3 arg3) \
{ \
long __res; \
__asm__ volatile ( "int $0x80" \
: "=a" (__res) \
: "0" (__NR_##name),"b" ((long)(arg1)),"c" ((long)(arg2)), \
"d" ((long)(arg3))); \
__syscall_return(type,__res); \
}
Whenever a system call with three arguments is made, the macro shown above is used to make the call. The syscall number is placed in eax, then each parameters in ebx, ecx, edx. And finally “int 0x80” is the instruction which makes the system call work. The return value can be collected from eax.
Every system calls are implemented in a similar way. Exit is a single parameter syscall and let’s see how it’s code will look like. It is as shown below.1
2
3
4
5
6 {
asm("movl $1,%%eax; /* SYS_exit is 1 */
xorl %%ebx,%%ebx; /* Argument is in ebx, it is 0 */
int $0x80" /* Enter kernel mode */
);
}
The number of exit is “1” and here, it’s parameter is 0. So we arrange eax to contain 1 and ebx to contain 0 and by int $0x80, the exit(0) is executed. This is how exit works.
参考:https://www.ibiblio.org/gferg/ldp/GCC-Inline-Assembly-HOWTO.html

