在虚拟机的创建与运行章节里面笼统的介绍了KVM在qemu中的创建和运行,基本的qemu代码流程已经梳理清楚,后续主要写一些硬件虚拟化的原理和代码流程,主要写原理和qemu控制KVM运行的的ioctl接口,后续对内核代码的梳理也从这些接口下手。
QEMU:git://git.qemu.org/qemu.git v2.4.0
KVM:https://git.kernel.org/pub/scm/linux/kernel/git/stable/linux-stable.git v4.2
1.VT-x 技术
Intel处理器支持的虚拟化技术即是VT-x,之所以CPU支持硬件虚拟化是因为软件虚拟化的效率太低。
处理器虚拟化的本质是分时共享,主要体现在状态恢复和资源隔离,实际上每个VM对于VMM看就是一个task么,之前Intel处理器在虚拟化上没有提供默认的硬件支持,传统 x86 处理器有4个特权级,Linux使用了0,3级别,0即内核,3即用户态,(更多参考CPU的运行环、特权级与保护)而在虚拟化架构上,虚拟机监控器的运行级别需要内核态特权级,而CPU特权级被传统OS占用,所以Intel设计了VT-x,提出了VMX模式,即VMX root operation 和 VMX non-root operation,虚拟机监控器运行在VMX root operation,虚拟机运行在VMX non-root operation。每个模式下都有相对应的0~3特权级。
为什么引入这两种特殊模式,在传统x86的系统中,CPU有不同的特权级,是为了划分不同的权限指令,某些指令只能由系统软件操作,称为特权指令,这些指令只能在最高特权级上才能正确执行,反之则会触发异常,处理器会陷入到最高特权级,由系统软件处理。还有一种需要操作特权资源(如访问中断寄存器)的指令,称为敏感指令。OS运行在特权级上,屏蔽掉用户态直接执行的特权指令,达到控制所有的硬件资源目的;而在虚拟化环境中,VMM控制所有所有硬件资源,VM中的OS只能占用一部分资源,OS执行的很多特权指令是不能真正对硬件生效的,所以原特权级下有了root模式,OS指令不需要修改就可以正常执行在特权级上,但这个特权级的所有敏感指令都会传递到root模式处理,这样达到了VMM的目的。
在KVM源代码分析1:基本工作原理章节中也说了kvm分3个模式,对应到VT-x 中即是客户模式对应vmx非root模式,内核模式对应VMX root模式下的0特权级,用户模式对应vmx root模式下的3特权级。
如下图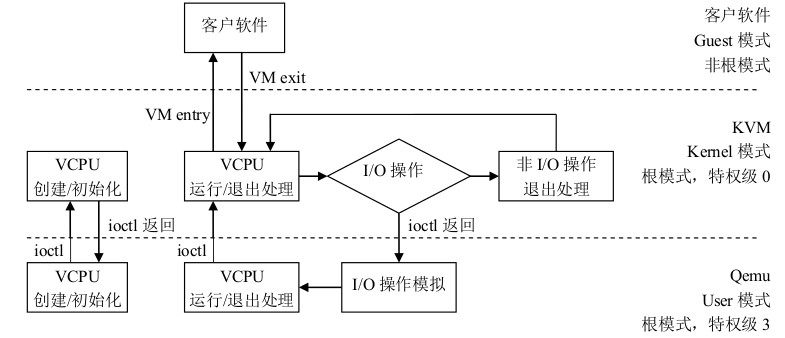
在非根模式下敏感指令引发的陷入称为VM-Exit,VM-Exit发生后,CPU从非根模式切换到根模式;对应的,VM-Entry则是从根模式到非根模式,通常意味着调用VM进入运行态。VMLAUCH/VMRESUME命令则是用来发起VM-Entry。
2.VMCS寄存器
VMCS保存虚拟机的相关CPU状态,每个VCPU都有一个VMCS(内存的),每个物理CPU都有VMCS对应的寄存器(物理的),当CPU发生VM-Entry时,CPU则从VCPU指定的内存中读取VMCS加载到物理CPU上执行,当发生VM-Exit时,CPU则将当前的CPU状态保存到VCPU指定的内存中,即VMCS,以备下次VMRESUME。
VMLAUCH指VM的第一次VM-Entry,VMRESUME则是VMLAUCH之后后续的VM-Entry。VMCS下有一些控制域:
col 1 | col 2 | col 3
———————- | ——————————————————– | —————————————————————–
VM-execution controls | Determines what operations cause VM exits | CR0, CR3, CR4, Exceptions, IO Ports, Interrupts, Pin Events, etc
Guest-state area | Saved on VM exits,Reloaded on VM entry | EIP, ESP, EFLAGS, IDTR, Segment Regs, Exit info, etc
Host-state area | Loaded on VM exits | CR3, EIP set to monitor entry point, EFLAGS hardcoded, etc
VM-exit controls | Determines which state to save, load, how to transition | Example: MSR save-load list
VM-entry controls | Determines which state to load, how to transition | Including injecting events (interrupts, exceptions) on entry
关于具体控制域的细节,还是翻Intel手册吧。
3.VM-Entry/VM-Exit
VM-Entry是从根模式切换到非根模式,即VMM切换到guest上,这个状态由VMM发起,发起之前先保存VMM中的关键寄存器内容到VMCS中,然后进入到VM-Entry,VM-Entry附带参数主要有3个:1.guest是否处于64bit模式,2.MSR VM-Entry控制,3.注入事件。1应该只在VMLAUCH有意义,3更多是在VMRESUME,而VMM发起VM-Entry更多是因为3,2主要用来每次更新MSR。
VM-Exit是CPU从非根模式切换到根模式,从guest切换到VMM的操作,VM-Exit触发的原因就很多了,执行敏感指令,发生中断,模拟特权资源等。
运行在非根模式下的敏感指令一般分为3个方面:
1.行为没有变化的,也就是说该指令能够正确执行。
2.行为有变化的,直接产生VM-Exit。
3.行为有变化的,但是是否产生VM-Exit受到VM-Execution控制域控制。
主要说一下”受到VM-Execution控制域控制”的敏感指令,这个就是针对性的硬件优化了,一般是1.产生VM-Exit;2.不产生VM-Exit,同时调用优化函数完成功能。典型的有“RDTSC指令”。除了大部分是优化性能的,还有一小部分是直接VM-Exit执行指令结果是异常的,或者说在虚拟化场景下是不适用的,典型的就是TSC offset了。
VM-Exit发生时退出的相关信息,如退出原因、触发中断等,这些内容保存在VM-Exit信息域中。
4.KVM_CREATE_VM
创建VM就写这里吧,kvm_dev_ioctl_create_vm函数是主干,在kvm_create_vm中,主要有两个函数,kvm_arch_init_vm和hardware_enable_all,需要注意,但是更先一步的是KVM结构体,下面的struct是精简后的版本。
struct kvm {
struct mm_struct *mm; /* userspace tied to this vm */
struct kvm_memslots *memslots; /*qemu模拟的内存条模型*/
struct kvm_vcpu *vcpus[KVM_MAX_VCPUS]; /* 模拟的CPU */
atomic_t online_vcpus;
int last_boosted_vcpu;
struct list_head vm_list; //HOST上VM管理链表,
struct kvm_io_bus *buses[KVM_NR_BUSES];
struct kvm_vm_stat stat;
struct kvm_arch arch; //这个是host的arch的一些参数
atomic_t users_count;
long tlbs_dirty;
struct list_head devices;
};
kvm_arch_init_vm基本没有特别动作,初始化了KVM->arch,以及更新了kvmclock函数,这个另外再说。
而hardware_enable_all,针对于每个CPU执行“on_each_cpu(hardware_enable_nolock, NULL, 1)”,在hardware_enable_nolock中先把cpus_hardware_enabled置位,进入到kvm_arch_hardware_enable中,有hardware_enable和TSC初始化规则,主要看hardware_enable,crash_enable_local_vmclear清理位图,判断MSR_IA32_FEATURE_CONTROL寄存器是否满足虚拟环境,不满足则将条件写入到寄存器内,CR4将X86_CR4_VMXE置位,另外还有kvm_cpu_vmxon打开VMX操作模式,外层包了vmm_exclusive的判断,它是kvm_intel.ko的外置参数,默认唯一,可以让用户强制不使用VMM硬件支持。
5.KVM_CREATE_VCPU
kvm_vm_ioctl_create_vcpu主要有三部分,kvm_arch_vcpu_create,kvm_arch_vcpu_setup和kvm_arch_vcpu_postcreate,重点自然是kvm_arch_vcpu_create。老样子,在这之前先看一下VCPU的结构体。
struct kvm_vcpu {
struct kvm *kvm; //归属的KVM\#ifdef CONFIG_PREEMPT_NOTIFIERSstruct preempt_notifier preempt_notifier;
\#endif
int cpu;
int vcpu_id;
int srcu_idx;
int mode;
unsigned long requests;
unsigned long guest_debug;
struct mutex mutex;
struct kvm_run *run; //运行时的状态
int fpu_active;
int guest_fpu_loaded, guest_xcr0_loaded;
wait_queue_head_t wq; //队列
struct pid *pid;
int sigset_active;
sigset_t sigset;
struct kvm_vcpu_stat stat; //一些数据
\#ifdef CONFIG_HAS_IOMEM
int mmio_needed;
int mmio_read_completed;
int mmio_is_write;
int mmio_cur_fragment;
int mmio_nr_fragments;
struct kvm_mmio_fragment mmio_fragments[KVM_MAX_MMIO_FRAGMENTS];
\#endif
\#ifdef CONFIG_KVM_ASYNC_PF
struct {
u32 queued;
struct list_head queue;
struct list_head done;
spinlock_t lock;
} async_pf;
\#endif
\#ifdef CONFIG_HAVE_KVM_CPU_RELAX_INTERCEPT
/*
\* Cpu relax intercept or pause loop exit optimization
\* in_spin_loop: set when a vcpu does a pause loop exit
\* or cpu relax intercepted.
\* dy_eligible: indicates whether vcpu is eligible for directed yield.
\*/
struct {
bool in_spin_loop;
bool dy_eligible;
} spin_loop;
\#endif
bool preempted;
struct kvm_vcpu_arch arch; //当前VCPU虚拟的架构,默认介绍X86
};
借着看kvm_arch_vcpu_create,它借助kvm_x86_ops->vcpu_create即vmx_create_vcpu完成任务,vmx是X86硬件虚拟化层,从代码看,qemu用户态是一层,kernel 中KVM通用代码是一层,类似kvm_x86_ops是一层,针对各个不同硬件架构,而vcpu_vmx则是具体架构的虚拟化方案一层。首先是kvm_vcpu_init初始化,主要是填充结构体,可以注意的是vcpu->run分派了一页内存,下面有kvm_arch_vcpu_init负责填充x86 CPU结构体,下面就是kvm_vcpu_arch:
struct kvm_vcpu_arch {
/*
\* rip and regs accesses must go through
\* kvm_{register,rip}_{read,write} functions.
\*/unsignedlong regs[NR_VCPU_REGS];
u32 regs_avail;
u32 regs_dirty;
//类似这些寄存器就是就是用来缓存真正的CPU值的unsignedlong cr0;
unsignedlong cr0_guest_owned_bits;
unsignedlong cr2;
unsignedlong cr3;
unsigned long cr4;
unsigned long cr4_guest_owned_bits;
unsigned long cr8;
u32 hflags;
u64 efer;
u64 apic_base;
struct kvm_lapic *apic; /* kernel irqchip context */
unsigned long apic_attention;
int32_t apic_arb_prio;
int mp_state;
u64 ia32_misc_enable_msr;
bool tpr_access_reporting;
u64 ia32_xss;
/*
\* Paging state of the vcpu
\*
\* If the vcpu runs in guest mode with two level paging this still saves
\* the paging mode of the l1 guest. This context is always used to
\* handle faults.
\*/
struct kvm_mmu mmu; //内存管理,更多的是附带了直接操作函数
/*
\* Paging state of an L2 guest (used for nested npt)
\*
\* This context will save all necessary information to walk page tables
\* of the an L2 guest. This context is only initialized for page table
\* walking and not for faulting since we never handle l2 page faults on
\* the host.
\*/
struct kvm_mmu nested_mmu;
/*
\* Pointer to the mmu context currently used for
\* gva_to_gpa translations.
\*/
struct kvm_mmu *walk_mmu;
struct kvm_mmu_memory_cache mmu_pte_list_desc_cache;
struct kvm_mmu_memory_cache mmu_page_cache;
struct kvm_mmu_memory_cache mmu_page_header_cache;
struct fpu guest_fpu;
u64 xcr0;
u64 guest_supported_xcr0;
u32 guest_xstate_size;
struct kvm_pio_request pio;
void *pio_data;
u8 event_exit_inst_len;
struct kvm_queued_exception {
bool pending;
bool has_error_code;
bool reinject;
u8 nr;
u32 error_code;
} exception;
struct kvm_queued_interrupt {
bool pending;
bool soft;
u8 nr;
} interrupt;
int halt_request; /* real mode on Intel only */
int cpuid_nent;
struct kvm_cpuid_entry2 cpuid_entries[KVM_MAX_CPUID_ENTRIES];
int maxphyaddr;
/* emulate context */
//下面是KVM的软件模拟模式,也就是没有vmx的情况,估计也没人用这一套
struct x86_emulate_ctxt emulate_ctxt;
bool emulate_regs_need_sync_to_vcpu;
bool emulate_regs_need_sync_from_vcpu;
int (*complete_userspace_io)(struct kvm_vcpu *vcpu);
gpa_t time;
struct pvclock_vcpu_time_info hv_clock;
unsigned int hw_tsc_khz;
struct gfn_to_hva_cache pv_time;
bool pv_time_enabled;
/* set guest stopped flag in pvclock flags field */
bool pvclock_set_guest_stopped_request;
struct {
u64 msr_val;
u64 last_steal;
u64 accum_steal;
struct gfn_to_hva_cache stime;
struct kvm_steal_time steal;
} st;
u64 last_guest_tsc;
u64 last_host_tsc;
u64 tsc_offset_adjustment;
u64 this_tsc_nsec;
u64 this_tsc_write;
u64 this_tsc_generation;
bool tsc_catchup;
bool tsc_always_catchup;
s8 virtual_tsc_shift;
u32 virtual_tsc_mult;
u32 virtual_tsc_khz;
s64 ia32_tsc_adjust_msr;
atomic_t nmi_queued; /* unprocessed asynchronous NMIs */
unsigned nmi_pending; /* NMI queued after currently running handler */
bool nmi_injected; /* Trying to inject an NMI this entry */
struct mtrr_state_type mtrr_state;
u64 pat;
unsigned switch_db_regs;
unsigned long db[KVM_NR_DB_REGS];
unsigned long dr6;
unsigned long dr7;
unsigned long eff_db[KVM_NR_DB_REGS];
unsigned long guest_debug_dr7;
u64 mcg_cap;
u64 mcg_status;
u64 mcg_ctl;
u64 *mce_banks;
/* Cache MMIO info */
u64 mmio_gva;
unsigned access;
gfn_t mmio_gfn;
u64 mmio_gen;
struct kvm_pmu pmu;
/* used for guest single stepping over the given code position */
unsigned long singlestep_rip;
/* fields used by HYPER-V emulation */
u64 hv_vapic;
cpumask_var_t wbinvd_dirty_mask;
unsigned long last_retry_eip;
unsigned long last_retry_addr;
struct {
bool halted;
gfn_t gfns[roundup_pow_of_two(ASYNC_PF_PER_VCPU)];
struct gfn_to_hva_cache data;
u64 msr_val;
u32 id;
bool send_user_only;
} apf;
/* OSVW MSRs (AMD only) */
struct {
u64 length;
u64 status;
} osvw;
struct {
u64 msr_val;
struct gfn_to_hva_cache data;
} pv_eoi;
/*
\* Indicate whether the access faults on its page table in guest
\* which is set when fix page fault and used to detect unhandeable
\* instruction.
\*/
bool write_fault_to_shadow_pgtable;
/* set at EPT violation at this point */
unsigned long exit_qualification;
/* pv related host specific info */
struct {
bool pv_unhalted;
} pv;
};
整个arch结构真是长,很适合凑篇幅,很多结构其他过程涉及到的再提吧,反正我也不知道。
kvm_arch_vcpu_init初始化了x86在虚拟化底层的实现函数,首先是pv和emulate_ctxt,这些不支持VMX下的模拟虚拟化,尤其是vcpu->arch.emulate_ctxt.ops = &emulate_ops,emulate_ops初始化虚拟化模拟的对象函数。
static struct x86_emulate_ops emulate_ops = {
.read_std = kvm_read_guest_virt_system,
.write_std = kvm_write_guest_virt_system,
.fetch = kvm_fetch_guest_virt,
.read_emulated = emulator_read_emulated,
.write_emulated = emulator_write_emulated,
.cmpxchg_emulated = emulator_cmpxchg_emulated,
.invlpg = emulator_invlpg,
.pio_in_emulated = emulator_pio_in_emulated,
.pio_out_emulated = emulator_pio_out_emulated,
.get_segment = emulator_get_segment,
.set_segment = emulator_set_segment,
.get_cached_segment_base = emulator_get_cached_segment_base,
.get_gdt = emulator_get_gdt,
.get_idt = emulator_get_idt,
.set_gdt = emulator_set_gdt,
.set_idt = emulator_set_idt,
.get_cr = emulator_get_cr,
.set_cr = emulator_set_cr,
.cpl = emulator_get_cpl,
.get_dr = emulator_get_dr,
.set_dr = emulator_set_dr,
.set_msr = emulator_set_msr,
.get_msr = emulator_get_msr,
.halt = emulator_halt,
.wbinvd = emulator_wbinvd,
.fix_hypercall = emulator_fix_hypercall,
.get_fpu = emulator_get_fpu,
.put_fpu = emulator_put_fpu,
.intercept = emulator_intercept,
.get_cpuid = emulator_get_cpuid,
};
x86_emulate_ops函数看看就好,实际上也很少有人放弃vmx直接软件模拟。后面又有mp_state,给pio_data分配了一个page,kvm_set_tsc_khz设置TSC,kvm_mmu_create则是初始化MMU的函数,里面的函数都是地址转换的重点,在内存虚拟化重点提到。kvm_create_lapic初始化lapic,初始化mce_banks结构,还有pv_time,xcr0,xstat,pmu等,类似x86硬件结构上需要存在的,OS底层需要看到的硬件名称都要有对应的软件结构。
回到vmx_create_vcpu,vmx的guest_msrs分配得到一个page,后面是vmcs的分配,vmx->loaded_vmcs->vmcs = alloc_vmcs(),alloc_vmcs为当前cpu执行alloc_vmcs_cpu,alloc_vmcs_cpu中alloc_pages_exact_node分配给vmcs,alloc_pages_exact_node调用__alloc_pages实现,原来以为vmcs占用了一个page,但此处从伙伴系统申请了2^vmcs_config.order页,此处vmcs_config在setup_vmcs_config中初始化,vmcs_conf->order = get_order(vmcs_config.size),而vmcs_conf->size = vmx_msr_high & 0x1fff,又rdmsr(MSR_IA32_VMX_BASIC, vmx_msr_low, vmx_msr_high),此处size由于与0x1fff与运算,大小必然小于4k,order则为0,然来绕去还是一个page大小。这么做估计是为了兼容vmcs_config中的size计算。
下面根据vmm_exclusive进行kvm_cpu_vmxon,进入vmx模式,初始化loaded_vmcs,然后用kvm_cpu_vmxoff退出vmx模式。
vmx_vcpu_load加载VCPU的信息,切换到指定cpu,进入到vmx模式,将loaded_vmcs的vmcs和当前cpu的vmcs绑定到一起。vmx_vcpu_setup则是初始化vmcs内容,主要是赋值计算,下面的vmx_vcpu_put则是vmx_vcpu_load的反运算。下面还有一些apic,nested,pml就不说了。
vmx_create_vcpu结束就直接回到kvm_vm_ioctl_create_vcpu函数,下面是kvm_arch_vcpu_setup,整个就一条线到kvm_arch_vcpu_load函数,主要有kvm_x86_ops->vcpu_load(vcpu, cpu)和tsc处理,vcpu_load就是vmx_vcpu_load,刚说了,就是进入vcpu模式下准备工作。
kvm_arch_vcpu_setup后面是create_vcpu_fd为proc创建控制fd,让qemu使用。kvm_arch_vcpu_postcreate则是马后炮般,重新vcpu_load,写msr,tsc。
如此整个vcpu就创建完成了。
6.KVM_RUN
KVM run涉及内容也不少,先写完内存虚拟化之后再开篇专门写RUN流程。
下一篇:
———-完———-
——————–下面未编辑的留存————————————-
给vmcs分配空间并初始化,在alloc_vmcs_cpu分配一个页大小内存,用来保存vm和vmm信息。
vmx->vmcs = alloc_vmcs();
if (!vmx->vmcs)
goto free_msrs;
vmcs_init(vmx->vmcs);
执行vm entry的时候将vmm状态保存到vmcs的host area,并加载对应vm的vmcs guest area信息到CPU中,vm exit的时候则反之,vmcs具体结构分配由硬件实现,程序员只需要通过VMWRITE和VMREAD指令去访问。
vmx执行完后,回到kvm_vm_ioctl_create_vcpu函数。kvm_arch_vcpu_reset对vcpu的结构进行初始化,后面一些就是检查vcpu的合法性,最后和kvm串接到一起。
vcpu的创建到此结束,下面说一下vcpu的运行。
VCPU一旦创建成功,后续的控制基本上从kvm_vcpu_ioctl开始,控制开关有KVM_RUN,KVM_GET_REGS,KVM_SET_REGS,KVM_GET_SREGS,KVM_SET_SREGS,KVM_GET_MP_STATE,KVM_SET_MP_STATE,KVM_TRANSLATE,KVM_SET_GUEST_DEBUG,KVM_SET_SIGNAL_MASK等,如果不清楚具体开关作用,可以直接到qemu搜索对应开关代码,一目了然。
KVM_RUN的实现函数是kvm_arch_vcpu_ioctl_run,进行安全检查之后进入__vcpu_run中,在while循环里面调用vcpu_enter_guest进入guest模式,首先处理vcpu->requests,对应的request做处理,kvm_mmu_reload加载mmu,通过kvm_x86_ops->prepare_guest_switch(vcpu)准备陷入到guest,prepare_guest_switch实现是vmx_save_host_state,顾名思义,就是保存host的当前状态。
kvm_x86_ops->prepare_guest_switch(vcpu);
if (vcpu->fpu_active)
kvm_load_guest_fpu(vcpu);
kvm_load_guest_xcr0(vcpu);
vcpu->mode = IN_GUEST_MODE;
/* We should set ->mode before check ->requests,
\* see the comment in make_all_cpus_request.
\*/
smp_mb();
local_irq_disable();
然后加载guest的寄存器等信息,fpu,xcr0,将vcpu模式设置为guest状态,屏蔽中断响应,准备进入guest。但仍进行一次检查,vcpu->mode和vcpu->requests等,如果有问题,则恢复host状态。
kvm_guest_enter做了两件事:account_system_vtime计算虚拟机系统时间;rcu_virt_note_context_switch对rcu锁数据进行保护,完成上下文切换。
准备工作搞定,kvm_x86_ops->run(vcpu),开始运行guest,由vmx_vcpu_run实现。
if (vmx->emulation_required && emulate_invalid_guest_state)
return;
if (test_bit(VCPU_REGS_RSP, (unsigned long *)&vcpu->arch.regs_dirty))
vmcs_writel(GUEST_RSP, vcpu->arch.regs[VCPU_REGS_RSP]);
if (test_bit(VCPU_REGS_RIP, (unsigned long *)&vcpu->arch.regs_dirty))
vmcs_writel(GUEST_RIP, vcpu->arch.regs[VCPU_REGS_RIP]);
判断模拟器,RSP,RIP寄存器值。
主要功能在这段内联汇编上
asm(
/* Store host registers */
"push %%"R"dx; push %%"R"bp;"
"push %%"R"cx nt" /* placeholder for guest rcx */
"push %%"R"cx nt"//如果vcpu host rsp和环境不等,则将其拷贝到vpu上
"cmp %%"R"sp, %c[host_rsp](%0) nt""je 1f nt""mov %%"R"sp, %c[host_rsp](%0) nt"
__ex(ASM_VMX_VMWRITE_RSP_RDX) "nt"//__kvm_handle_fault_on_reboot write host rsp"1: nt"/* Reload cr2 if changed */
"mov %c[cr2](%0), %%"R"ax nt"
"mov %%cr2, %%"R"dx nt"
//环境上cr2值和vpu上的值不同,则将vpu上值拷贝到环境上
"cmp %%"R"ax, %%"R"dx nt"
"je 2f nt"
"mov %%"R"ax, %%cr2 nt"
"2: nt"
/* Check if vmlaunch of vmresume is needed */
"cmpl $0, %c[launched](%0) nt"
/* Load guest registers. Don't clobber flags. */
"mov %c[rax](%0), %%"R"ax nt"
"mov %c[rbx](%0), %%"R"bx nt"
"mov %c[rdx](%0), %%"R"dx nt"
"mov %c[rsi](%0), %%"R"si nt"
"mov %c[rdi](%0), %%"R"di nt"
"mov %c[rbp](%0), %%"R"bp nt"
\#ifdef CONFIG_X86_64
"mov %c[r8](%0), %%r8 nt"
"mov %c[r9](%0), %%r9 nt"
"mov %c[r10](%0), %%r10 nt"
"mov %c[r11](%0), %%r11 nt"
"mov %c[r12](%0), %%r12 nt"
"mov %c[r13](%0), %%r13 nt"
"mov %c[r14](%0), %%r14 nt"
"mov %c[r15](%0), %%r15 nt"
\#endif
"mov %c[rcx](%0), %%"R"cx nt" /* kills %0 (ecx) */
/* Enter guest mode */
//此处和cmpl $0, %c[launched](%0)是对应的,此处选择进入guest的两种模式
//RESUME和LAUNCH,通过__ex __kvm_handle_fault_on_reboot执行
"jne .Llaunched nt"
__ex(ASM_VMX_VMLAUNCH) "nt"
"jmp .Lkvm_vmx_return nt"
".Llaunched: " __ex(ASM_VMX_VMRESUME) "nt"
//退出vmx,保存guest信息,加载host信息
".Lkvm_vmx_return: "
/* Save guest registers, load host registers, keep flags */
"mov %0, %c[wordsize](%%"R"sp) nt"
"pop %0 nt"
"mov %%"R"ax, %c[rax](%0) nt"
"mov %%"R"bx, %c[rbx](%0) nt"
"pop"Q" %c[rcx](%0) nt"
"mov %%"R"dx, %c[rdx](%0) nt"
"mov %%"R"si, %c[rsi](%0) nt"
"mov %%"R"di, %c[rdi](%0) nt"
"mov %%"R"bp, %c[rbp](%0) nt"
\#ifdef CONFIG_X86_64
"mov %%r8, %c[r8](%0) nt"
"mov %%r9, %c[r9](%0) nt"
"mov %%r10, %c[r10](%0) nt"
"mov %%r11, %c[r11](%0) nt"
"mov %%r12, %c[r12](%0) nt"
"mov %%r13, %c[r13](%0) nt"
"mov %%r14, %c[r14](%0) nt"
"mov %%r15, %c[r15](%0) nt"
\#endif
"mov %%cr2, %%"R"ax nt"
"mov %%"R"ax, %c[cr2](%0) nt"
"pop %%"R"bp; pop %%"R"dx nt"
"setbe %c[fail](%0) nt"
: : "c"(vmx), "d"((unsigned long)HOST_RSP),
//下面加了前面寄存器的指针值,对应具体结构的值
[launched]"i"(offsetof(struct vcpu_vmx, launched)),
[fail]"i"(offsetof(struct vcpu_vmx, fail)),
[host_rsp]"i"(offsetof(struct vcpu_vmx, host_rsp)),
[rax]"i"(offsetof(struct vcpu_vmx, vcpu.arch.regs[VCPU_REGS_RAX])),
[rbx]"i"(offsetof(struct vcpu_vmx, vcpu.arch.regs[VCPU_REGS_RBX])),
[rcx]"i"(offsetof(struct vcpu_vmx, vcpu.arch.regs[VCPU_REGS_RCX])),
[rdx]"i"(offsetof(struct vcpu_vmx, vcpu.arch.regs[VCPU_REGS_RDX])),
[rsi]"i"(offsetof(struct vcpu_vmx, vcpu.arch.regs[VCPU_REGS_RSI])),
[rdi]"i"(offsetof(struct vcpu_vmx, vcpu.arch.regs[VCPU_REGS_RDI])),
[rbp]"i"(offsetof(struct vcpu_vmx, vcpu.arch.regs[VCPU_REGS_RBP])),
\#ifdef CONFIG_X86_64
[r8]"i"(offsetof(struct vcpu_vmx, vcpu.arch.regs[VCPU_REGS_R8])),
[r9]"i"(offsetof(struct vcpu_vmx, vcpu.arch.regs[VCPU_REGS_R9])),
[r10]"i"(offsetof(struct vcpu_vmx, vcpu.arch.regs[VCPU_REGS_R10])),
[r11]"i"(offsetof(struct vcpu_vmx, vcpu.arch.regs[VCPU_REGS_R11])),
[r12]"i"(offsetof(struct vcpu_vmx, vcpu.arch.regs[VCPU_REGS_R12])),
[r13]"i"(offsetof(struct vcpu_vmx, vcpu.arch.regs[VCPU_REGS_R13])),
[r14]"i"(offsetof(struct vcpu_vmx, vcpu.arch.regs[VCPU_REGS_R14])),
[r15]"i"(offsetof(struct vcpu_vmx, vcpu.arch.regs[VCPU_REGS_R15])),
\#endif
[cr2]"i"(offsetof(struct vcpu_vmx, vcpu.arch.cr2)),
[wordsize]"i"(sizeof(ulong))
: "cc", "memory"
, R"ax", R"bx", R"di", R"si"
\#ifdef CONFIG_X86_64
, "r8", "r9", "r10", "r11", "r12", "r13", "r14", "r15"
\#endif
以上代码相对容易理解的,根据注释大致清楚了具体作用。
然后就是恢复系统NMI等中断:
vmx_complete_atomic_exit(vmx); vmx_recover_nmi_blocking(vmx); vmx_complete_interrupts(vmx);
回到vcpu_enter_guest,通过hw_breakpoint_restore恢复硬件断点。
if (hw_breakpoint_active())
hw_breakpoint_restore();
kvm_get_msr(vcpu, MSR_IA32_TSC, &vcpu->arch.last_guest_tsc);
//设置vcpu模式,恢复host相关内容
vcpu->mode = OUTSIDE_GUEST_MODE;
smp_wmb();
local_irq_enable();
++vcpu->stat.exits;
/*
\* We must have an instruction between local_irq_enable() and
\* kvm_guest_exit(), so the timer interrupt isn't delayed by
\* the interrupt shadow. The stat.exits increment will do nicely.
\* But we need to prevent reordering, hence this barrier():
\*/
barrier();
//刷新系统时间
kvm_guest_exit();
preempt_enable();
vcpu->srcu_idx = srcu_read_lock(&vcpu->kvm->srcu);
/*
\* Profile KVM exit RIPs:
\*/
if (unlikely(prof_on == KVM_PROFILING)) {
unsigned long rip = kvm_rip_read(vcpu);
profile_hit(KVM_PROFILING, (void *)rip);
}
kvm_lapic_sync_from_vapic(vcpu);
//处理vmx退出
r = kvm_x86_ops->handle_exit(vcpu);
handle_exit退出函数由vmx_handle_exit实现,主要设置vcpu->run->exit_reason,让外部感知退出原因,并对应处理。对于vpu而言,handle_exit只是意味着一个传统linux一个时间片的结束,后续的工作都是由handle完成的,handle_exit对应的函数集如下:
staticint (*kvm_vmx_exit_handlers[])(struct kvm_vcpu *vcpu) = {
[EXIT_REASON_EXCEPTION_NMI] = handle_exception,
[EXIT_REASON_EXTERNAL_INTERRUPT] = handle_external_interrupt,
[EXIT_REASON_TRIPLE_FAULT] = handle_triple_fault,
[EXIT_REASON_NMI_WINDOW] = handle_nmi_window,
[EXIT_REASON_IO_INSTRUCTION] = handle_io,
[EXIT_REASON_CR_ACCESS] = handle_cr,
[EXIT_REASON_DR_ACCESS] = handle_dr,
[EXIT_REASON_CPUID] = handle_cpuid,
[EXIT_REASON_MSR_READ] = handle_rdmsr,
[EXIT_REASON_MSR_WRITE] = handle_wrmsr,
[EXIT_REASON_PENDING_INTERRUPT] = handle_interrupt_window,
[EXIT_REASON_HLT] = handle_halt,
[EXIT_REASON_INVD] = handle_invd,
[EXIT_REASON_INVLPG] = handle_invlpg,
[EXIT_REASON_VMCALL] = handle_vmcall,
[EXIT_REASON_VMCLEAR] = handle_vmx_insn,
[EXIT_REASON_VMLAUNCH] = handle_vmx_insn,
[EXIT_REASON_VMPTRLD] = handle_vmx_insn,
[EXIT_REASON_VMPTRST] = handle_vmx_insn,
[EXIT_REASON_VMREAD] = handle_vmx_insn,
[EXIT_REASON_VMRESUME] = handle_vmx_insn,
[EXIT_REASON_VMWRITE] = handle_vmx_insn,
[EXIT_REASON_VMOFF] = handle_vmx_insn,
[EXIT_REASON_VMON] = handle_vmx_insn,
[EXIT_REASON_TPR_BELOW_THRESHOLD] = handle_tpr_below_threshold,
[EXIT_REASON_APIC_ACCESS] = handle_apic_access,
[EXIT_REASON_WBINVD] = handle_wbinvd,
[EXIT_REASON_XSETBV] = handle_xsetbv,
[EXIT_REASON_TASK_SWITCH] = handle_task_switch,
[EXIT_REASON_MCE_DURING_VMENTRY] = handle_machine_check,
[EXIT_REASON_EPT_VIOLATION] = handle_ept_violation,
[EXIT_REASON_EPT_MISCONFIG] = handle_ept_misconfig,
[EXIT_REASON_PAUSE_INSTRUCTION] = handle_pause,
[EXIT_REASON_MWAIT_INSTRUCTION] = handle_invalid_op,
[EXIT_REASON_MONITOR_INSTRUCTION] = handle_invalid_op,
};
有handle_task_switch进行任务切换,handle_io处理qemu的外部模拟IO等,具体处理内容后面在写。
再次退回到__vcpu_run函数,在while (r > 0)中,循环受vcpu_enter_guest返回值控制,只有运行异常的时候才退出循环,否则通过kvm_resched一直运行下去。
if (need_resched()) {
srcu_read_unlock(&kvm->srcu, vcpu->srcu_idx);
kvm_resched(vcpu);
vcpu->srcu_idx = srcu_read_lock(&kvm->srcu);
}
再退就到了kvm_arch_vcpu_ioctl_run函数,此时kvm run的执行也结束。
KVM cpu虚拟化的理解基本如上,涉及到的具体细节有时间后开篇另说。
KVM源代码分析未完待续

