‘内存存取顺序(Memory ordering)’一词说的是处理器通过系统总线进行读取(加载)以及写回(存储)到系统内存里面。Intel 64以及32位系统根据架构的实现,支持多种存储顺序模型。例如,intel 386处理器强制使用“程序顺序”(强顺序),就是说读写系统总线的顺序按照全部环境中CPU指令流产生的顺序。
后来为了指令执行的效率,IA32架构允许脱离“强顺序”,在奔腾4、Xeon以及P6系列处理器中,称作“处理器顺序”。处理器顺序不同的方式,称作“内存存取顺序模型”,他们都允许增强执行,例如 允许读操作在可以缓存的写操作之前。所有这些不同模型的目的就是增强指令执行速度,同时保持存储内容的一致性,即使在多核系统中亦然。
8.2.1和8.2.2章节描述在intel486、奔腾、Core2 Due、Atom、Core Due、奔腾4、Xeon以及P6系列处理器中内存存取模型的实现。8.2.3章节会给出具体的存储模型的例子。8.2.4章节是关于字节操作的特殊处理。8.2.5章节讨论一些特殊指令的使用会影响存储模型的行为。
8.2.1 奔腾以及486处理器上的存储模型
奔腾和486处理器遵循“处理器顺序”的内存存取模型,但在大多数情况下他们是按照“强顺序”模型来运行的。加载和存储是按照系统总线顺序,但除了以下情况:加载允许放在缓存的写之前,当所有的写操作都被缓存,但是不可以跟加载操作是同一个地址。
对于I/O操作,无论是加载还是存储都是程序顺序。
8.2.2 P6系列以及最新系列CPU的存储顺序
Intel Core2 Due、Atom、Core Duo、奔腾4以及P6系列处理器上使用的处理器顺序模型可以被称为“带写缓存转发的存储顺序(write ordered with store-buffer forwarding)”(很拗口,可能读到后面才能理解上啥意思),我们本节来看这种模型。
在单处理器系统中存储区域被定义为“可缓存的回写”。这种存取模型遵循下面的法则。注意,单核或者多核处理器存储模型中涉及到的名词“处理器”都是指逻辑处理器。比如,一个物理处理器支持多核或者支持intel 超线程技术(HT),那么它都被看做是“多核处理器”
- 加载操作之间不可以重排序。
- 存储不可以跟加载操作重排序。
- 存储操作间除下列例外情况之外,不可以重排。
- 流存储通过非时态(non-temporal)的move 指令,MOVINTI,MOVNTQ,MOVNTDQ, MOVNTPS以及MOVNTPD。
- 字符串操作(详见8.2.4.1)
- 不允许CLFLUSH指令的存储操作的重排序;当使用CLFLUSHOPT指令时,存储操作可以被重排序,并且刷新缓存而不是直接存储。CLFLUSH指令的执行不可以被重新排序。当刷新不同缓存线的时候,CLFLUSHOPT指令的执行可以被重新排序。
- 加载操作可以与不同地址的存储操作重排序,不可以与相同地址的存储重新排序。
- 在I/O操作、锁指令或者串行指令时加载和存储都不可以重排序。
- 加载不可以早于LFENCE和MFENCE指令。
- 存储和CLFUSH、CLFLUSHOPT不能早于LFENCE、SFENCE以及MFENCE指令。
- LFENCE指令不可以早于加载。
- SFENCE指令不可以早于存储或者CLFLUSH、CLFLUSHOPT指令。
- MFENCE指令不能早于加载、存储或者CLFLUSH和CLFLUSHOPT指令。
对于多核处理器,还要遵守下面规则:
- 多核处理器中的每一个核都与单核处理器遵守同样的准则。
- 各个核中的存储顺序是跟所有处理器中存储顺序是一致的。
- 单个处理器上的存储操作与其他处理器上的存储操作顺序无关。
- 内存存取顺序遵从因果关系(memory ordering respects transitive visibility)。
- 在同一个处理器上的任何两个存储操作都可以看做是有确定顺序的,但整个存储操作看来却不一定。
- 锁指令具有绝对的执行顺序。
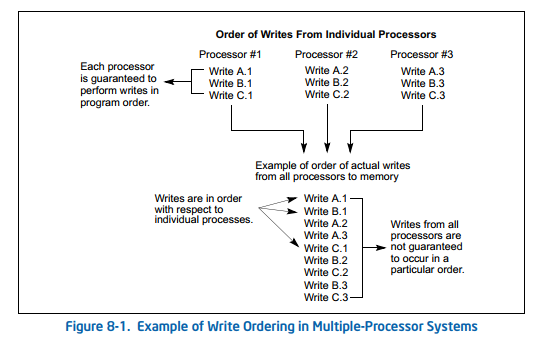
看一个例子,图8-1.有三个处理器,并且每个处理器中有三个存储操作,分别是A,B,C。单独来说,处理器是按照程序顺序来进行存储操作,但由于总线仲裁以及内存访问机制,三个处理器对同一个内存的访问,即使是执行同一段代码,可能每次都不太一样。
本章处理器顺序模型是奔腾和486所使用的,在奔腾4、Xeon以及P6系列处理器中,仅仅加强了如下内容:
- 增加了推理加载,但依然遵守上午策略。
- 存储缓存转发,当一个读取操作在存储操作之后。
- 长字符串的乱序存储以及move操作(详见8.2.4)
8.2.3 举例说明存储顺序策略
本章举例说明8.2.2中的内存存取顺序策略。目的是给软件开发人员深入理解内存存取顺序是如何影响不同指令序列的结果的。
这些例子仅限于有回写缓存能力的内存区域。读者需要理解他们仅仅是软件可见的行为。即便某个例子说明不可以重排的两次方访问,逻辑处理器也可能会重排。此时软件是无法察觉这样的重排操作发生。
8.2.3.1 假设、术语以及注意事项
如前文所述,本章所述的内容仅限于回写缓存(WB)的存储区域。此时仅提交原始的加载和存储操作,同时为“读-改-写”指令加锁。同时并不提交任何如下指令:字符串的乱序存储、用non-temporal hint访问存储、处理器加载页表以及更新段、页结构。
在本节例子中,Intel64存储顺序模型保证下列内存访问指令视为一次单独的访问操作:
- 加载或存储一个字节的指令
- 加载或存储一个word(2字节),并且他们的地址是2字节对齐的。
- 加载或存储一个doubleword(4字节),并且他们的的地址是4字节对齐的
- 加载或存储一个quadword(8字节),并且他们的地址8字节对齐的。
任何带锁的指令(例如XCHG或者其他读后写的指令都会有一个LOCK前缀指令),看上去是作为一次单独的、不会被中断的指令序列。
其他指令也可能是有多次内存存取访问组合来实现的。从内存存取顺序的观点来看,并不能保证其操作的顺序,也不能保内存存取操作的顺序跟程序加载的顺序一致。
8.2.3.2至8.2.3.7使用MOV指令来举例。通过内存存取操作来说明存储器策略以及其他各种存取指令的基础。8.2.3.8和8.2.3.9使用XCHG指令举例,用来说明那些带锁的以及读后写的指令。
本章节中“处理器”是指逻辑处理器。例子是用intel-64汇编语言,并且使用如下写法: - 使用’r’开头的参数,例如r1 r2看作是寄存器,只有处理器可见。
- 存储器地址记作x,y,z
- 存储记为 mov [_x],val, 意思是把val存到寄存器的_x地址中
- 加载记作 mov r,[_x], 意思是把内存地址_x中的值加载到寄存器r中
正如前文所述,例子只是设计软件可见的行为。当文中说“把两个存储操作重排”意思是“两个存储操作从软件的角度看上去被重新排列执行顺序了”。
8.2.3.2 相似的加载或者存储都不可以重排序
Intel-64 内存存取顺序模型不允许同样类型的加载或者存储指令重新排列。也就是说,在程序中加载或者存储都是按照程序顺序,用下面的里说明:
| Processor0 | Processor1 |
|---|---|
| mov [_x],1 | mov r1,[_y] |
| mov [_y],1 | mov r2,[_x] |
| 初始值 x=y=0 | |
| r1 = 1 并且 r2 = 0 是不允许的 |
只有当处理器0的两个存储操作重排序,或者处理器1的两个加载操作重排的时候,返回值是非法的。
如果r1 = 1,那么对y的存储操作早于y的加载。因为Intel-64内存存取顺序模型不允许存储操作重排序,所以存储X的操作也应早于y,同事由于存储顺序模型不允许加载重排序,所以x的存储也早于x的加载,所以 r2 = 1.
8.2.3.3 存储不能重排到加载之前
Intel-64 存储顺序模型确保处理器的存储操作不会在同一个处理器家在之前。
| 处理器0 | 处理器1 |
|---|---|
| mov r1,[x] | mov r2,[y] |
| mov [y],1 | mov [x],1 |
| 初始值 x=y=0 | |
| r1 = 1 并且 r2 = 1 非法 |
假设 r1 = 1
- 因为r1 = 1, 处理器1的x存储早于处理器0的x的加载
- 因为intel-64 存取顺序模型避免存储操作被重排序到同一个处理器的加载操作之前,处理器1的y的加载早于对x的存储。
- 同理,处理器0的x的加载早于y的存储
- 因此,处理器1中y的加载在处理器0y存储之前,所以r2 = 0.
8.2.3.4 加载可以被重排序到不同地址的存储之前
intel-64存取顺序重排允许加载操作重排序到不同地址的存储之前,但不允许重排序到同一个地址的存储之前。
| 处理器0 | 处理器1 |
|---|---|
| mov [x],1 | mov [y],1 |
| mov r1 [y] | mov r2,[x] |
| 初始值 x=y=0 | |
| r1 = 0 并且 r2 = 0 允许 |
在每个处理器中,对于不同的地址的加载和存储操作是允许重排序的。任何交替执行方式也因此被允许。其中一种交替执行的方式,是两个加载在两个存储之前。这样的结果就是r1和r2都返回0
| 处理器0 |
|---|
| mov [x], 1 |
| mov r1,[x] |
| 初始值 x = 0 |
| r1 = 0 非法 |
Intel64 存取顺序模型不允许加载重排序到同一个地址的存储之前,因此r1 = 1必须被加载。
8.2.3.5 允许处理器内转发
存取顺序模型允许两个处理器并行的存储,但从各自处理器看来存储的顺序是不一样的。每一个处理器可能都认为自己的存储操作早于另一个处理器的存储操作。举例说明:
| 处理器0 | 处理器1 |
|---|---|
| mov [x], 1 | mov [y],1 |
| mov r1,[x] | mov r3,[y] |
| mov r2,[y] | mov r4,[x] |
存储顺序模型不会在执行顺序上增加限制。这个情况允许处理器0认为它的存储操作早于处理器1,同事处理器1认为它的存储操作早于处理器0.这使得r2=0并且r4=0成为可能。
事实上,这个例子可以看做是存储缓存区转发。当处理器临时含有存储缓存的时候,它可以传递给处理器自己的加载操作,但它不能被其他的处理器看到并加载。
8.2.3.6 内存存取顺序可见
存取顺序模型确保存储的可见性。一个处理器上的存储操作需要被所有的处理器可见,并且按照一定的合理的顺序。举例说明:
| 处理器0 | 处理器1 | 处理器2 |
|---|---|---|
| mov [x],1 | mov r1,[x] | |
| mov [y],1 | mov r2,[y] | |
| mov r3,[x] | ||
| 初始值 x=y=0 | ||
| r1 = 1并且r2 =1并且 r3=0 非法 |
假设 r1=1 并且 r2 = 1.
- 因为r1=1,处理器0的存储早于处理器1的加载
- 因为存取顺序模型避免存储被重排序到加载之前,处理器1中的加载早于存储。因此处理器0的存储的存储势必早于处理器1的存储。
- 因为处理器0的存储早于处理器1的存储,存储顺序模型确保处理器0的存储在所有处理器看来早于处理器1.
- 因为r2 = 1, 处理器1的存储早于处理器2的加载操作。
- 因为Intel-64存储模型避免加载操作重排序,处理器2的加载顺序执行。
- 综上分析,处理器0的存储在处理器2的加载之前,这就意味着r3 = 1.
8.2.3.7 存储顺序一致
正如8.2.3.5中提到,存取顺序模型允许两个处理器看到不同的处理顺序。然而,任意两个存储操作必须在所有处理器看来有一致的执行顺序。举例说明:
| 处理器0 | 处理器1 | 处理器2 | 处理器3 |
|---|---|---|---|
| mov [x],1 | mov [y],1 | mov r1,[x] | mov r3,[y] |
| mov r2,[y] | mov r4,[x] | ||
| 初始值 x=y=0 | |||
| r1=1并且r2=0并且r3=1并且r4=0 非法 |
根据8.2.3.2中讨论的原则
- 处理器2中的两个加载不可以被重排序
- 处理器3中的两个加载不可以被重排序
- 如果 r1=1 并且 r2=0,根据处理器2的加载,处理器0的存储在处理器1的存储之前。
- 同理,r3=1并且r4=0,意味着,根据处理器1的加载,处理器1的存储在处理器0的存储之前。
因此,内存存取顺序模型确保两个存储在所有处理器看来具有同样的顺序,所以这组返回值非法。
8.2.3.8 带锁的指令具有绝对顺序
存取顺序模型确保所有的处理器处理对待锁指令的时候保持一致,包括大于8字节的或者没有自然对齐的指令。举例说明:
| 处理器0 | 处理器1 | 处理器2 | 处理器3 |
|---|---|---|---|
| xchg [x],r1 | xchg [y],r2 | ||
| mov r3,[x] | mov r5,[y] | ||
| mov r4,[y] | mov r6,[x] | ||
| 初始值 r1=r2=1, x=y=0 | |||
| r3=1 并且 r4=0 并且r5=1 并且r6=0 非法 |
处理器2 和处理器3必须确保两个xchg指令的执行顺序。这里假定处理器1的xchg指令早于处理器3中y的加载指令发生。
- 如果r5=1, 处理器1的xchg执行早于处理器3的加载,先发生。
- 因为intel64 内存顺序模型避免加载重排序,处理器3中按顺序加载。所以处理器1的xchg早于处理器3中x的加载,先发生。
- 根据假设,处理器0中的xchg早于处理器1xchg,并且是在处理器3的加载之前,所以r6=1
8.2.3.9 加载和存储不允许跟锁指令重排序
存取顺序模型避免加载和存储操作跟其前后的锁指令重排序。举例说明:
第一个例子说明,加载操作不可以跟之前的锁指令重排序
| 处理器0 | 处理器1 |
|---|---|
| xchg [x],r1 | xchg [y],r3 |
| mov r2,[y] | mov r4,[x] |
| 初始值 x=y=0, r1=r3=1 | |
| r2=0 并且 r4=0 非法 |
根据8.2.3.8的解释,锁指令有绝对的执行顺序,这里假设处理器0上的schg0先发生。
因为intel64 内存存取顺序模型避免处理器1的加载跟锁指令重排序,处理器0上的xchg在处理器1的加载之前,这意味着,r4=1.
相似的,如果处理器1的xchg先发生, 也可得非法返回值。
第二个例子说明存储操作不能跟之前的锁指令重排序。
| 处理器0 | 处理器1 |
|---|---|
| xchg [x],r1 | mov r2,[y] |
| mov [y],1 | mov r3,[x] |
| 初始值 x=y=0, r1=1 | |
| r2=1 并且r3=0 非法 |
假设r2=1
- 因为r2=1, 处理器0的y存储早于处理器1的y的加载。
- 因为内存存取顺序模型避免存储跟前面的锁指令重排序,处理器0上的xchg早于y的加载发生。
- 因为内存存取顺序模型避免加载重排序,处理器1上按顺序加载,并且处理器1上的对x的xchg操作早于处理器1的x的加载,因为r3=1
8.2.4 快速字符串操作和乱序存储
SDM 第一卷7.3.9.3 章节中描述描述了优化重复执行fast-string操作。该章节中阐述,存储产生fast-string操作,可能会乱序执行。软件则需要串行化存储顺序,所以不可以使用字符操作来存储整个的数据结构。数据和信号量应该分隔开。有顺序依赖的代码在进行字符串操作之后,需要写到一个单独的信号量中,以保证所有处理看到正确的数据顺序。加载和存储操作的原子化,仅能保证本地字符串数据元素,并且他们还得在用一个缓存中。
8.2.4.1 和4.2.4.2提供的进一步的说明和例子。
8.2.4.1 字符串的内存存取模型
本章讲述字符串操作的内存存取模型。存取规则如下:
- 单个字符串的存储可能是乱序执行。
- 一个独立的字符串的存储,例如保存一个连续的字符串,并不希望乱序。所有的存储操作都必须在完成上一次存储之后,进行新的存储操作。
- 字符串操作不可以跟其他存储操作重排序。
快速字符串操作(例如,使用MOVS/STOS指令,并且使用REP前缀)可能会被中断或者异常而打断。中断是准确的,但可能会延迟,比如中断可能在每个几次循环或者在每操隔几次操作之后,在缓存的边界触发。不同的实现方式可能配置不同,或者甚至选择不延迟中断handle,所以软件不要依赖延迟。如果运行到中断或者陷入的处理函数,源/目的寄存器指向下一个等待处理的字符串元素。当EIP存储在指向指令的栈中,并且ECX寄存器还持有上一条指令成功时的值。中断或者陷阱处理函数应该引起字符串指令被恢复到它之前中断的地方。
字符串操作内存存取顺序规则(上面的2,3点)可以举例说明。如果一个快速字符串操作在第k次遍历时被中断,那么中断处理函数中的存储操作变为可见的(*)。
只有当快速字符串操作开启时,存储单个字符串的操作可能乱序执行。(上面的1)
8.2.4.2 举例说明字符串操作中的内存存取策略
To-do
8.2.5 加强型和减弱型内存存取模型
Intel64和32体系结构提供了多种加强型或者减弱型的内存存取模型,以应对不同的程序条件。这些机制包括:
- I/O指令、锁指令,锁前缀以及串行化指令强制较强的存取顺序
- SFENCE指令(IA32体系结构的奔腾3系列处理器)和LFENCE以及MFENCE指令(奔腾4处理器引入)提供内存存取顺序以及对某些特定指令的串行化的能力。
- 内存类型鸡寄存器(Memory type range registers,MTRR)可以在特定的物理内存区域中被用于增强或者减弱型的内存存取顺序。 MTRR只在奔腾4,Xeon 以及P6系列处理器中。
- 页属性表(page attribute table,PAT) 可以被用于页表或者页表组的增强型以及减弱型的内存存取顺序。PAT只在奔腾4,Xeon 以及P6系列处理器中。
这些机制可以如下使用:
映射到设备或者其他IO设备的内存地址通常顺序敏感。I/O指令(IN和OUt指令)强制使用写顺序。在执行一个I/O指令之前,处理器会等待所有的之前指令完成,并且所有的缓存写回内存中。但除了页表的获取和遍历指令。
多核处理器系统的同步机制可以依赖强内存存取顺序模型。这里应用程序可以使用锁指令,例如XCHG指令以及所前缀,来确保读-改-写才做。锁指令通常操作起来像I/O操作,他们同样等待之前的指令结束并且把所有的缓存写回内存中。
程序的同步也可以使用串行化指令(8.3章节)。这些指令通常在紧急的步骤中,或者边界任务,以确保所有之前的指令都完成,然后再跳转到新的代码段或者上下文切换。类似I/O或者锁指令,处理器会在之前的指令完成之前一直等待,并且把所有的缓存写回到内存中,然后再执行串行的指令。
SFENCE、LFENCE以及MFENCE指令提供了高效的方法来确保通常情况下产生的弱顺序以及数据的处理过程中的加载和存储顺序。这些指令的方法如下: - SFENCE:串行化所有的发生在SFENCE指令之前的程序指令流中的存储操作,但不影响加载操作。
- LFENSE: 串行所有发生在在LFENCE指令之前的程序指令流中的加载操作,但不影响存储操作。
- MFENCE: 串行化所有发生在MFENCE指令之前的存储和加载操作。
注意,相比CPUID指令,SFENCE、LFENCE以及MFENCE指令提供了更搞笑的方法控制内存存取顺序。
MTRR在P6系列处理器中杯引入,来定义指定物理内存区域的缓存特性。下面的两个例子说明内存类型的设置可以使用增强或者减弱的内存存取顺序。
- 非缓存(uncached)内存类型,强制内存访问中使用强顺序模型。这里所有读写非缓存内存区域,不可能使用乱序或者预测的方法。这种类型的内存可以被用于I/O设备映射。
- 回写(write back,WB)内存类型是弱存取顺序。这时,加载可以使用预测的方法,并且存储可以被缓存或者合并。这种类型的内存,缓存锁作为原子操作,不可以被中断,可以用来指令同步,同时降低的程序运行的速度,例如XCHG指令,它会在整个读-改-写的操作中锁住总线。使用写回内存类型,如果缓存命中,那么XCGH指令只是锁缓存,而并不需要锁总线
PAT是在奔腾3处理器中被引入的,来增强缓存特性,可以用在页表或者页表组中。PAT机制通常用在页表层的增强特性,与MTRR相关。
Intel推荐软件运行在Intel Core 2 Duo, Intel Atom, Intel Core Duo, Pentium 4, Intel Xeon, and P6 family等系列处理器中,假定处理器顺序或者更弱的内存存取顺序模型。上述处理器没有实现强内存存取模型,除非使用非缓存内存。尽管其中一些处理器支持处理器顺序,但intel不保证未来的处理器会支持这种模型。为了让软件可以一直到未来的处理器,推荐操作系统提供紧急区域以及资源控制构造和基于I/O的API ,锁以及串行化指令,用来多处理器间同步访问共享的内存区域。并且,软件不应该依赖处理器顺序,当硬件系统不支持该种内存存取顺序模型。

